| Submission Procedure |
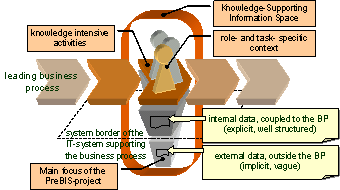
Modelling and Implementing Pre-built Information Spaces. Architecture and Methods for Process Oriented Knowledge ManagementKarsten Böhm Wolf Engelbach Jörg Härtwig Martin Wilcken Martin Delp Abstract: Process-oriented Knowledge Management aims to provide adequate information for employees, especially in weakly structured and information-intensive business processes. Beside a technical software solution, which uses a pre-structured, context-aware and collaborative information space that combines processes, domain specific semantic structures and document parts, this requires a methodology to model the process and other context-dimensions, such as roles. Moreover, a guideline and clear service modules are necessary to introduce process-oriented Knowledge Management in companies, especially in small and medium-sized enterprises (SME). Such solutions were developed in the cooperative research project PreBIS (Pre-Built Information Space). Key Words: modelling method, introduction method, context-awareness, information retrieval, ontology, collaborative filtering, business processes, knowledge management Category: H.3, H.4, I.2.4, I.2.7, I.7, J.1 1 IntroductionProcess-oriented Knowledge Management strives to align the fields of Knowledge Management with the domain of business process management in order to support knowledge-intensive business processes during their execution. The applied research project "Pre Built Information Space" (PreBIS) is a cooperative research and development project that follows the concept of closely aligning information sources to the value creating processes within an organisation. Page 605 In the understanding of this contribution we follow the definition of [Probst et. al. (03)], which defines knowledge as the application of appropriate information by human beings in a given situation. The PreBIS-project tries to support this process within a company setting by structuring and filtering the information. Relevant information supports activities within knowledge-intensive business processes and requires sound information to make meaningful decisions. Therefore, the PreBIS-system is an IT-based Knowledge Management System that supports knowledge-intensive operational business processes. Such processes (e.g. product development and marketing) are usually weakly structured, which means they consist of only a few distinguishable activities and have a high variability during their execution. The basic idea of PreBIS (see [Fähnrich, Böhm 03], [Hoof et. al. 03]), as illustrated below in figure 1, is to provide knowledge-intensive activities with information from both internal and external sources by dynamically aligning them to a leading business process. Throughout this paper this concept, resembling a "cloud of relevant information around each activity" will be referred to as an information space. Since this structure is created using manual modelling methods as well as automatic analysis techniques for unstructured information prior to the usage within the system the term pre-built is used to emphasize our approach. Figure 1: Aligning information sources to a knowledge-intensive business process using role- and task-specific contexts Furthermore, the information space exhibits properties of adaptation and collaboration by exploiting the concept of context, which describes the current situation of a certain employee in the execution of a certain activity within a certain business process. Context in this meaning should reflect a part of the organisational knowledge and describe how information provision works in the company as a whole in contrast to the capabilities of the individual user. The contextual situation is described as a tuple of a role and an activity that is maintained by the leading business process. A more detailed description of context for the domain of information management will be given in section 5. This context information will be used to adjust the information space dynamically, depending on the information needs. Feedback will be obtained as the user interacts with the PreBIS-system. This data will be aggregated and used to readjust the components of the information space and their relationships with each other. Page 606 Over time the information space therefore adapts to typical usage patterns (property of adaptation by means of collaborative filtering). Since all operations on the information space are carried out at the level of organisational roles, which each individual user is assigned to while executing a process activity, the PreBIS-system implements a collaborative system. This system enables the users to cooperate implicitly within groups with similar information needs while explicitly interacting with the information space on an individual level. The information space can thus be seen as a collaborative knowledge store for experiences gained when looking for the needed information. Primarily PreBIS is an IT-system that enables the effective and efficient management of information in organisations, for example by intelligent adaptation and combination of ontologies (modelling top-down concepts) and networks of terms (automatic bottom-up analysis) [Hoof et. al. 03]. In addition to the technical realisation, methodological solutions were developed to support the notion of pre-building for information spaces: First, a method is needed to model the context that consists of process, roles, ontologies and information request types. Second, a guideline and precise service modules are necessary to introduce process-oriented Knowledge Management in companies, especially in small and medium-sized enterprises (SME) that do not have specialized management capacities to implement such systems. The paper is structured as follows: section 2 investigates what has been done already by investigating related work and research activities within the field of process-oriented Knowledge Management. Section 3 addresses the current situation within companies and gathers the demands from users with a focus on SME. In section 4 research objectives and goals are defined based on the observations of the current situation. A description of the prototypical software solution that has been developed will follow in section 5. The modelling technique for constructing the initial information space (pre-building strategy) will be the topic of the next section, which then will be followed by an explanation of the methodology for introducing the PreBIS-solution in a company based on flexible service modules in section 7. The conclusion in section 8 summarizes the results and gives an outlook on challenges within the field of business process oriented knowledge infrastructures that will require further research. 2 Related WorkInformation management which adapts to a context and is aligned with business processes is becoming more and more relevant in industrial applications (see e.g. [Schütt 04], [Schomisch, Hoffmann 04]). The practical use is based on a broad range of scientific approaches to process-oriented Knowledge Management; an overview is given in [Remus 02]. The difference of the PreBIS-approach compared to this related work is discussed with regard to the two methodological aspects of the paper, the modelling and the introduction of process-oriented Knowledge Management. Related work, relevant for the PreBIS-projects can be found in different fields which are discussed briefly below:
Page 607 Additionally, measures are defined to introduce leadership, information technology, enterprise culture, controlling, and organisation (e.g. Fraunhofer IPK, see [Mertins et. al. 03]). This approach uses processes to structure Knowledge Management, while PreBIS aims to support the processes themselves with adequate information. Page 608 The approaches discussed above emphasise either organisational or technical solutions. However, they all stress the necessity of adaptation to a changing context, which is important for the modelling. They also stress the need to reduce effort for the system introduction, which is a relevant factor for the implementation method. All these approaches have some influence on the PreBIS methods. A difference is the level of abstraction where PreBIS aims to find a company specific solution based on a general framework but does not get too much into permanently changing details. Inspired by the academic discussion, and based on existing products, some software solutions also realise several aspects of context-oriented information supply today. In Enterprise or Employee Portals, a role and task-based view on available information is presented (see [Gurzki, Özkan 2003]). Often this concentrates on editorially created content but integration of weakly structured content is realised more and more often. Such portal management solutions range from personalised entertainment platforms to project cooperation tools. The functionalities are widely influenced by the background of a product, such as document management, information retrieval, application integration and content management [Eberhardt et. al. 02]. PreBIS aims to offer technical solutions that goes, at least in form of prototypes, beyond existing products, which also requires further steps in modelling and introduction methods. 3 Challenges and Requirements for Process Oriented Information Management in CompaniesThe availability of digital information is quite common in many companies. Presentations, documents, manuals, analysis, correspondence and other relevant information which can be understood as codified knowledge is stored on file servers, in the intranet, in special applications or CRM-, ERP- and Document Management Systems. The internet and external databases are frequently used sources of information, too. A central challenge is the efficient retrieval in these distributed and often weakly structured data. This is especially relevant for employees with knowledge-intensive tasks who need to search for different kinds of information regularly, such as product managers, sales persons, editors, engineers and consultants.
1For other papers on this issue see www.jusc.org, volume 10 (2004), issue 1. Page 609 Such knowledge-intensive processes regularly require consultations with internal and external partners. Also an individual user might search for information at changing level of detail, according to the progress within the business process. Furthermore users might also present their findings to other people with their different roles and views in mind. Therefore it is a high-ranked concern of information managers to retrieve good answers even on vague information requests. In addition, there is a demand to find information from different internal and external sources, but to also find indications on the information accuracy and reliability [Engelbach, Delp 03]. In PreBIS, the roles must not be fixed to the user; instead a person should be able to shift between views on the information space. Some of the most crucial problems with information management in companies are, for example, high costs for the manual creation and maintenance of knowledge structures, the inability of automatic adoption to changing usage patterns and the complex modification of underlying information collections (e.g. in case of growing content or content topic shifts). PreBIS addresses these challenges by its approach not to change the existing setting of information generating and storing, but to optimise retrieval and use of information with the support of context. In the PreBIS project, automatic combination of concepts (high level knowledge structures activated from the context) and topics (extracted from the underlying document collection) is used. Starting with information requests from a specified context and using feedback information from the presented results, the system is able to rank the relevance of activated concepts and topics regarding to the request, the personal context, and the process. This continuous evaluation improves the processes and knowledge infrastructure by adapting to typical usage patterns. Information retrieval is often understood as an individual, independent, short term search process. Large link lists to entire documents are narrowed down manually to a manageable set of possibly matching results. PreBIS is going to ease the retrieval processes by bearing in mind contextual aspects that are omnipresent within organisations. In addition, the types, the granularities and the amount of requested information often rely on the context: employees may look for technical issues, for administrative issues, for abstracts or detailed specifications [Zagos, Kiehne 03]. Moreover, some basic collaborative types of process oriented information handling are defined to support the exchange and collaborative use of information objects (see section 5). A number of similarities were discovered in six medium-sized companies by investigating the possible support of information-intensive business processes with an IT-System like PreBIS: Such processes (e.g. product development and marketing) are usually weakly structured, seldom well and never formalised-documented. Many different software applications (e.g. Lotus Notes or Microsoft Exchange, Content Management and Customer Relationship Management, Enterprise Resource Planning, Fileserver, Intranet) are used, but a central process execution system is missing. Knowledge Management is often associated with Intranet, and the person in charge of the intranet is often the main knowledge manager. This is also the bottom line and starting point for modelling and introduction. Business process-oriented knowledge infrastructures follow a complex approach that is based on some conditions, such as stable and ideally modelled business processes. Since formal specifications of business processed are often missing in SME, it might impose another barrier to start with Business Process-oriented Knowledge Infrastructures. Page 610 PreBIS tries to overcome this aspect by incorporating automatic methods for knowledge extraction and structuring. It turned out, that formalized business processes (as well as ontologies) in medium-sized companies are less determined than initially assumed, especially in information intensive processes. Therefore, to base knowledge management on processes, one first needs to implement a basic process management including process descriptions, process managers and performance indicators. Such an initial description and the continuous update of process description can be understood as a main element of knowledge collection. Furthermore, any process infrastructure can be used as an element of knowledge infrastructure; strong support is given by any database (e.g. customer relation management systems, KAIZEN-Tools, intranets and so on). Preconditions of utilisation of such tools as knowledge infrastructure are the wide acceptance amongst employees and the promotion by the management. Nevertheless, there are some aspects that distinguish the companies, especially regarding the homogeneity of wording and concepts (ontological or terminological issues): in some companies different concepts for the same objects are used within the same department, in others there is a strict internal wording and a different corporate wording for external communication exist, a third company might use an established industry wording. Also the role descriptions vary, from simple to much elaborated models. The PreBIS methods must cope with these variations. 4 Research ObjectivesThis section introduces some research objectives extracted from the current situation (see section 1) and the demands of companies with respect to the use of business process oriented knowledge infrastructures (see section 3). Goals for the project PreBIS are derived and will be presented afterwards. Weakly structured but knowledge intensive processes, such as product development, innovation management or marketing activities would benefit most from a business process supportive knowledge infrastructure. Weakly structured processes differ from well structured process in terms of number of influencing factors such as target dates, number and education of involved employees, quality and character of produced products or services, and so on. Still, the support of weakly structured processes requires a highly sophisticated infrastructure like IT systems, which only pays for a big number of concurrent process instances. Nevertheless, there is a lack of powerful process-supporting tools for the support of business processes, which are easy to implement and easy to maintain. Therefore alternative solutions have to be proposed that allow smaller solutions to be built, that are also suitable for SME. The design and implementation of a knowledge infrastructure, according to the demands of business process models, will support the work of most companies throughout their value chain as shown in the previous section. The ongoing work shows that even companies with highly sophisticated organisations hardly have the necessary preparation at their disposal (e.g. process descriptions, glossaries, or ontologies). PreBIS therefore embarks on the strategy of an automated information extraction and recombination. This approach will disburden the employees from complex process-oriented knowledge documentation and will therefore support the basic Knowledge Management operations by fostering information documentation as well as information communication during information searches within internal and external information repositories. Page 611 PreBIS does not aim to change the existing setting of information generation and storage, but to optimise the way it can be accessed and used by utilizing the retrieval context as a filter function. The PreBIS-solution instead intends to support the processes with adequate information (alignment of process activities and relevant information). Ideally, such context information is delivered by process driven IT-Systems, but in reality this will often need to be modelled within the system. Therefore the PreBIS methods of modelling the specific context are at a level that is abstract enough to allow a stable organisation of the information supply. PreBIS does not intend to combine company specific software applications, but to make the information from different sources available instead. The information retrieval does not steer the process itself but specifies the request and uses the answer. The types, the granularities and the amount of requested information are specified according to the context: employees may look for technical issues, for administrative issues, for abstracts or detailed specifications. The focus of PreBIS is clearly on IT-based solutions and not so much on supporting the direct contact between employees. PreBIS models the user in its role within the business processes and then presents information according the role-specific ontology. Also the learning algorithm is role-oriented. Users are not fixed to roles but are able to shift between role-based views on the information space. The PreBIS approach is not made specifically for single companies but looks for individual solutions based on a general framework. Beside the technical solution, many organisational aspects needed to be tackled to realise a holistic approach and ease the implementation in a company setting. This contribution describes the two major aspects modelling and introduction, which are needed for an appropriate business model (see section 7). The alignment of process activities, carried out by an employee in a certain organisational role, with relevant information in this context will be primarily realised by the use of the information space model. This data structure can be interpreted as an accessing structure or map that works like glue between activity and information. Since information spaces are employed at the level of organisational roles, not individual users, they can be used as a joint knowledge memory that will aid communities to exchange experiences explicitly. Moreover, basic operations can be defined that work on these information or knowledge objects within the contextualized information space to utilize sharing of concepts and shaping of the networked structure during its use. 4.1 Goals and Concepts of PreBIS ryAmong the challenges in the area of Knowledge Management, the creation and maintenance of structured information spaces is a central topic. PreBIS follows a new approach for the growing field of data driven knowledge acquisition and dissemination. The technical system PreBIS puts the focus on the following three areas of innovation: Page 612
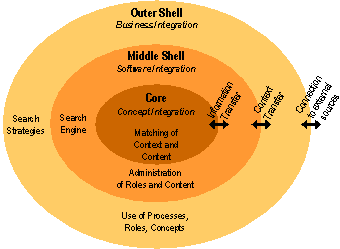
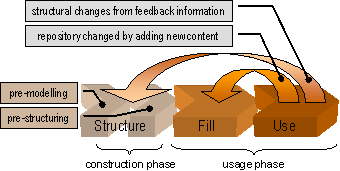
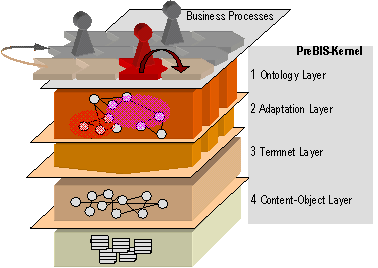
5 The Architecture of the PreBIS-SystemThis section introduces the architecture of the PreBIS-system. A modular approach is used to reduce the complexity of the system and will be described in the next subsection. Afterwards, the phase-model that is utilized to guide the pre-building process of the information space is explained and leads to the description of the PreBIS-kernel. It represents the core of the system and serves as the implementation of the concept of an information space. Special attention is paid to the dynamic coupling of the kernel to business processes which serve as provider of context information and are therefore crucial for the configuration of the information space. Finally, basic operations on the information space are described, which can be interpreted as generic interactions on information objects within a collaborative knowledge space. 5.1 PreBIS ModulesThe PreBIS-architecture, which has been developed in a joint research project, can be understood as a model with interdependent layers that enclose each other and lead to the idea of a shell metaphor, as illustrated in figure 2. The shell model consists of three major layers. The Outer Shell is concerned with business strategies and decision about business goals and the organisational environment. Page 613 Therefore this layer outlines the prerequisites for the modelled structure in business processes and information models, also referred to as ontologies, for a certain enterprise [Ngonga, Fähnrich 03]. Together with these models, the information logistic has to be adjusted to these business processes. Information logistic will be understood in this contribution as an abstract formal description about which information or knowledge is necessary for whom at which set of activities along a certain business process. Figure 2: The shell model with three interdependent layers of PreBIS-modules, enclosing each other The process of building an ontology can be supported with a collection of relevant terms from the vocabulary used within the company. Such a glossary subsumes the domain specific terminology and can be used as a reference document to capture conceptual knowledge. Such knowledge can be gained by analysing documents and data from file systems, data bases and other IT-applications used in the different company departments. Especially, when large volumes of data are concerned, a support of this process by automatic methods should be used to extract lists of important terms, which then can be used by consultants and domain experts to build up the information logistic that is aligned to the business process. A method overview of a knowledge strategy process for analysing and structuring business knowledge in enterprises is given in [Hofer-Alfeis 02]. The Middle Shell addresses technology constraints and specifications in order to connect components modelled in the business layer with the PreBIS-kernel functions. It primarily realises the embedding of the PreBIS-system in the IT-environment and in the operational workflow of the enterprise. This integration links the PreBIS-system to existing information sources, but is also responsible for the common set of commodity functions of a typical Information- or Knowledge Management System, such as security and rights management. Thus, the functions of this module can be subjected to the area of Enterprise Application Integration. Page 614 The Core, also referred to as the PreBIS-kernel, extends established technologies and standards and implements a new method for information spaces that combines semantic technologies (top-down approach and semi automatically modelled; producing business processes and ontologies) with statistical methods of information extraction (bottom-up and automatically derived; generating taxonomies and classifications). The resulting structure is overlaid with an adaptive context filtering mechanism to realise a role- and task-oriented operations (e.g. Information Retrieval and Exploration). The basic functionality of the core is to deliver fine grained pieces of information to the user while respecting his current information demand which is derived a from context. Thus it is supporting the knowledge worker while carrying out information intensive tasks and can be classified as an operational IT-based Knowledge Management System. 5.2 A Phase-Model for Pre-Building and Using PreBISThe creation of the information space depends on the right interpretation of the context from the leading business process which describes the information need of the user. Such context information is often implicit and specific for a certain role and activity and can therefore not be determined fully at the runtime of the system. But since the needed structural data can be found in formal business process models, job descriptions, role profiles etc., this data can be used to build up the information space before its utilisation (thus, the name pre-built information space). A phase model with an initial construction phase and a usage phase is proposed for the composition information spaces (see also [Böhm, Fähnrich 03]). As illustrated in figure 3, the phase model consists of three successive stages: Structure, Fill and Use (following the model of [Staab et. al. 01] for the creation and maintenance of ontologies). Figure 3: The successive stages of the phase-model for pre-building adaptive information spaces Structuring the information space in the initial phase is the main task in the business layer according to the shell metaphor. A large challenge is to pre-structure knowledge as a basic part of a knowledge repository [Davenport, Völpel 02], organisational memory [Habermann 01] or an information space [Hoof et. al. 03]. The business processes are the most important components with a focus on knowledge-intensive tasks, since information provision has to be aligned along with process activities, as explained before. Page 615 Therefore the processes have to be modelled or re-modelled with respect to the kind of data and the information source needed, as well as the information flow between different activities of the process. Since typically more than one participant can be involved in the flow of the business process or the assignment to a task, individual profiles are grouped to organisational roles, which share a common part of expertise, responsibility and knowledge demand. Expert interviews with representatives of each role must be held in order to capture role specific explicit knowledge in a role-specific ontology. An ontology therefore reflects the view of a group of knowledge workers of relevant objects in the enterprise. This "view of the world" represents a common understanding in terms of concepts and their relationships, domain specific terminology (e.g. technical jargon), environment, methods, authorities etc. Different role-specific ontologies mirror different views on the company. For example, a business manager in a chip producing company is interested in features and solutions or predictions about a new microprocessor. In contrast the technical officer rather needs information about manufacturing techniques, physical limits and new technologies. Both have different approaches to the same physical object (the microchip). It is important to point out, that the role-specific ontologies are linked to business processes, more precisely; each knowledge-intensive activity is bound to task-relevant concepts, thus, providing direction signs, markers and annotations to ease the task of information retrieval as well as navigation within the data sources. The methodology to build up the information space is described in section 6. Whereas the capturing of explicit knowledge and organisational structures is a manual top-down modelling approach, the analysis of content from the various information sources can be supported by automatic methods, which employ a button-up approach. Such a bottom-up structure is created by analysing all documents and defined data sources that the PreBIS-System should provide access to in the usage phase. The output of this statistical motivated algorithm (see [Biemann et. al. 04] for a detailed description) is a companywide role-independent network of related terms, or termnet. This graph-like data structure can be interpreted as a machine-readable thesaurus, which can be generated automatically from arbitrary sources of unstructured information. It contains statistically significant word forms (terms) as nodes and relates them (as weighted edges) according to the frequency of co-occurrences on sentence-level and direct neighbourhood within the text. The termnet can be used to represent a contextual word meaning in the PreBIS-kernel, which will be described below, and to assist the conceptual modelling of the domain ontologies (see section 6). Since the approach operates by means of statistical algorithms attention must also be paid to the number of documents available (the more, the better) and the document formats of the structured or unstructured data, which has to be converted prior to the analysis process. The Fill stage started after the Structure phase populates the information space with the information object that will be retrieved from internal information sources. The documents are broken up into smaller content objects also called assets, according to the syntactical structure of the document. The disassembling process yields atomic items like single sentences or paragraphs that can be assumed to contain a semantic assertion. Content objects are therefore semantically more compact information units, compared to whole documents. Providing content objects yield the advantage of a more efficient transmission since they are usually smaller than documents. Page 616 Furthermore since the user does not need to search within the document for the right section to satisfy his information demand, information provision will be more precisely, too. Finally, automatic reporting will be easier, as content object from different documents can be assembled into a new document that reflects the search question. For example, as a search result the business manager gets five hits. One hit is an 80-page document but instead of having to download the large document, he will get as a response a content object containing only the appropriate paragraph. Here the user recognizes two advantages: the client-application (e. g. the web browser) loads the content object notably faster and there is no need to search again in the 80-page document. The content objects are stored in the data layer. The last step in the Fill stage is indexing the domain of content objects with a search engine to guarantee an efficient retrieval. After the completion of the Fill-phase the information space is pre-modelled (business processes, information flow and ontologies as well as adaptors to internal and external information sources) and pre-structured (company-wide documents and data are analysed, broken up into context units and indexed) and ready for use. During the usage phase, implicit and explicit feedback information will be collected that affects the previous stages as illustrated by the arrows in Figure 3 and thus realises an adaptive information space. 5.3 Architecture of the PreBIS-KernelThe PreBIS-System is implemented as a client-server application with a web-application as front-end for the user. Therefore no client-side installation will be required and the application can be accessed in the intranet of the company or even on the internet, if secure communication channels are used. The PreBIS-kernel itself is implemented as a module that can be embedded into another Information Management System (Middle shell) and communicates with other components using standard protocols, such as Web Services. This section will describe the core functions of the PreBIS-kernel and demonstrate the handling of a request sent by a knowledge worker using the PreBIS-system. Before describing the different layers of the core-system, shown in figure 4, a definition of the concept context will be given, as it plays a central role for the functionality of the system. Finally, it will be explained how a business process can be used as a context provider for the PreBIS-kernel. 5.3.1 A Definition of ContextIn order to provide a user which is executing an activity within a business process with the right information the PreBIS-kernel should receive the information about the current context of the business process, referred to as business context. With the business context the kernel can make a prediction even if the user does not send an explicit search request. As there are many definitions on the term context in the literature, a clarification is needed about the use in this contribution: What is context and, in particular, business context, and where does the context comes from? Within the project the following definition will be used: Page 617 Context is a set of facts (environment variables, identifiers, notations etc.) or a special case (competences or an actual state) that describes a situation or an event in a way to make it interpretable. Three types of context are distinguished:
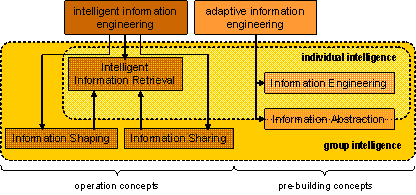
The business context corresponds to static context and has four parameters: the process name, the role of the user, the active task and (optional) additional information from the process instance. Figure 4: Architecture overview of the PreBIS-kernel and dynamic coupling to the business process execution system 5.4 Functionality of the PreBIS-KernelThe main function of the PreBIS-kernel is the contextual information provision according to the active task of a knowledge worker. The dynamics of the information space emerges from the collaboration on a role-specific level and over the coupling to the business context. Adaptability is another feature implemented in the kernel. It uses learning algorithms on the information space data structure to apply the usage information gathered by explicit and implicit feedback mechanisms. Page 618 Current Information Retrieval Systems enable users to find information in large collections of information sources. A Search query is formulated by the user to specify his information demand. Several query languages exit, but often keywords or simple phrases can be used to start a search process. This search strategy, also called Pull-Strategy requires the user to actively search for information. The PreBIS-System implements a Pull-Strategy too, but in addition to that it can also provide information by exploiting the current business context, thus realising a Push-Strategy, too. Since context changes can be automatically sent to the PreBIS-System, an appropriate information provision can be realised without the need for an explicit user interaction. The information about the current business context will be routed to the ontology layer (layer 1 in figure 4). The first layer encapsulates methods which gather information from the correlated business process (process name or correlation ID are part of the business context) and the referenced role-dependant ontology. Thus, the ontology layer extracts the relevant concepts from that ontology. If no query was sent by the user, the kernel can operate on the concepts that were activated by the business context. Assuming the PreBIS-server received a query from the client, the kernel continues to extend it to a search string which contains the search phrase with the relevant and weighted concepts in a special order. At this point we should once more consider our example mentioned above. The business manager (role of the user) needs information about the new microprocessor and has sent the query string "chip_xyz". The ontology layer extends the given query to "<chip_xyz> <product information> <export transaction>", because its current activity in the business process is the innovation of the international sales and distribution. This modified query will be sent to the adaptation layer. The adaptation layer (layer 2 in figure 4) is maintaining connections between the concepts from the ontology layer and the terms found in the termnet (layer 3 in figure 4). These connections are associated with a weight that reflects the relevance of the associated terms for to a concept. The initial weights will be set using a semi-automatic method (see [Fillies et. al. 03]); a learning algorithm will later be used to adjust the weights according to the usage patterns of concepts and term. The concepts from the ontology layer and the relations between them were modelled top-down under role-dependant constraints. In contrast, the termnet was built bottom-up automatically, based mainly on the document collection within the company. It is not role-dependant. These connections are strengthened or weakened depending on explicit feedback from users and additional heuristics (implicit feedback). The longer the PreBIS-System is used, the better the connections are adjusted to typical usage pattern. As for the search string " <chip_xyz> <product information> <export transaction>": the right connection will be picked for each phrase. These connections are used to expand the search string with more words, e. g. "<sales volume>, <product dimensions>, <export manager>" from the termnet. After that, the termnet layer must run a special function called spread activation. This function will check each phrase of the search string against the termnet to look up words within certain distance boundaries. This way, the function can retrieve words, which may be synonyms, homonyms or hyponyms etc. to the given phrase. The major task of the lowest layer (layer 4 in figure 4) in the architecture is to provide prerequisites for the search string to conduct the search process by an embedded third party search engine. The search will be performed on the content objects and added external information sources. Page 619 5.5 Linking the PreBIS-Kernel to the Business ProcessesThere are (at least) two ways for answering the question about the origin of the context information and how it can be obtained by the PreBIS-kernel. The simpler solution is a so called Process Stepper, which is a small application that runs on the client-side along with the PreBIS-client or as an integrated application. A more extensive scenario incorporates the use of a Process Control System (PCS) or a Workflow System such as Microsoft BizTalk. Both of them have to interact with the PreBIS-System over a web service using SOAP and both have to interpret the business process modelled during the Structure stage. The method the web service implements expects the four parameters of a business context mentioned above; the role and the task parameter being the most important ones. 5.5.1 Process StepperThe Process Stepper is an application that provides a stepwise execution of a business process that can be used in small enterprises that do not have a process execution system to structure their knowledge intensive activities into a more process oriented fashion. In addition to that, the Process Stepper can be used to simuqlate and test the behaviour of the PreBIS-System without an extensive IT-environment. To be used, the application must be started and configured by the user. The unique parameter needed to configure the web service interface is the URL of the PreBIS-server. He must then load the business process from the process repository of the company. Afterwards, the user can step through the business process in the given sequence. With each new step the Process Stepper sends the new context information to the PreBIS-kernel. The disadvantage of this solution is the need to manually confirm each completed task because changing one value of the context vector (process, role, task, add_info) causes a new business context, which must be sent to the PreBIS-System to re-adjust the information space. 5.5.2 Process Control SystemThis subsection describes a more elaborated solution that can be used in larger enterprises with a complex IT-structure embedding numerous application systems that interact with each other. For productivity and control flow purposes often a PCS (e. g. Microsoft BizTalk) is used. Alternatively, an Enterprise Resource Planning System can be used to impose the control flow. In either case two facts are essential: It must be the leading system from the viewpoint of the user and it must support a superset of Business Process Execution Language for Web Services (BPEL4WS) standard [Curbera et al. 03]. The business processes modelled in the Structure stage cannot be read by such a PCS. Without adding information that declares the PreBIS-System as a new communication partner, no information about the current business context can be sent to it. These special activities are called context hooks and will be configured to link the PreBIS-server at run-time in order to be able to send the context information before a new activity is started. In contrast to the smaller scenario above, the first parameter here is not the process name but the correlation ID, to identify the right process instance. Since the necessary transformation can be done automatically, no additional modelling effort is introduced. A description that performs this transformation can be found in [Böhm, Härtwig 05]. Page 620 Provided that the PCS is able to process-models that confirm to the BPEL4WS-standard, they can also execute the transformed business processes and therefore establish a dynamic communication link with the PreBIS-System that transmits the business context information to the PreBIS-kernel. 5.6 Basic Operations for the Information SpaceIn addition to the classical information retrieval process (keyword based search) and the navigation within the information space (explorative search) the PreBIS project elaborated how the cooperation between communities of users with similar interests could be further supported in the area of business process oriented knowledge infrastructures. Typical questions that arise in this environment are: How can the PreBIS-System directly support users during their work and how can the PreBIS-System improve cooperation between users with information interchange? Since the PreBIS-System is neither a Groupware System that provides means of direct communication or information interchange nor an expert system, that provides the user with explicit knowledge, the focus is rather to assist them in the core business processes in order ease the access to and the handling with relevant information, from which the needed knowledge can be (re)constructed. A set of basic operations on the pre-built information space has been developed to support the users and to foster cooperation at the level of information interchange. These generic operations can be divided into operation concepts and pre-building concepts. Another classification could be done along the dimension of individual or group intelligence. Figure 5: Overview of the basic operations on the pre-built information space The concept of Intelligent Information Engineering subsumes the support on information intensive work in a business process along two lines: The user can be seen as an individual, while the method Intelligent Information Retrieval is supporting him. At the same time a user can be a member of a team or a community, which can share information as well as shape information to increase the effectiveness of cooperative work. Adaptive Information Engineering, on the other hand, combines two concepts that enable explicit interaction with objects in the information space and thus fostering the use of the information space as a knowledge base for individual and cooperative use. Page 621 The operations, which are shown in an overview in figure 5, will be shortly introduced here. A more concise description can be found in [Härtwig, Fähnrich 03], [Hoof et. al. 03] and [Fähnrich, Böhm 03]:
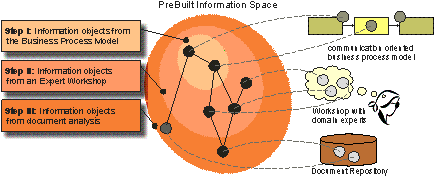
6 Modelling Methodology for Pre-built Information SpacesThe PreBIS-approach draws heavily from pre-building information spaces to supply the users with information that reflect their actual and anticipated demands with respect to their current working context. As the information space will adjust over time to the needs and usage patterns of users in various roles, this dependency will be especially high after the deployment phase of the solution, as the construction of an initial information space is crucial for the system to work efficiently. Page 622 In order to prevent the creation of yet another entry barrier for the application of Knowledge Management solutions, especially in SME, it is essential to minimize the modelling efforts needed to create the initial information space. This can be accomplished by combining modelling approaches from the field of business process modelling (see [Krallmann et. al. 02]) and ontology engineering (see [Staab et. al. 01]) with text-mining methods (see [Böhm et. al. 02]). Figure 6: An iterative, stepwise modelling methodology captures information objects from the business process, extends them using ontological concepts and links them to the terminology in an underlying document collection The methodology for the preparation of the information space consists of three steps and starts with the knowledge-intensive (part of a) business process which is modelled using a business process modelling technique which focuses on information objects and their flow between process activities (communication structure analysis, CSA, see [Hoyer 88], [Wyssusek 01]). This methodology suits the aspects of building a business process oriented knowledge infrastructure especially well, since it focuses on the flow of information (objects) rather that on the organisation of task-sequences. This initial information model can be extended with relevant domain concepts gained from expert workshops (stored in an ontology) and are rooted within the document repository that contains the relevant information by linking information objects to the terminology used in the documents. The steps for the creation and iterative refinement of the information space are illustrated in figure 6 and described below:
Page 623 Examples for such information objects could be "standard parts" or "mounting elements". Usually these information objects carry a high level of abstraction since they tend to aggregate groups of real physical objects. The modelling approach for pre-built information spaces introduced here, focuses on two new aspects in the area of knowledge-intensive business processes: First, obtaining relevant information objects directly from the business process and thus generating an agile Knowledge Infrastructure, which is directly coupled with the value generating business processes in the company. Second, an information space is build up by connecting information objects over different layers of abstraction from the general concepts bound to the activities within the business process to the terminological realisations in the document repository. Page 624 7 Modular Implementation MethodologyImplementing an information system like PreBIS in an enterprise cannot be done 'out of the box'. Instead, an analysis of the organisational and technical infrastructure of the enterprise has to be accomplished first. For instance business processes and roles have to be extracted, and the existing hardware and software environment needs to be considered. A variety of tasks has to be completed during implementation, and as every enterprise requires a specific fulfilment of these tasks, a specific implementation practice for each of them is needed. To allow an efficient implementation of PreBIS in such a setting, the necessary work has been systematised and mapped in a flexible implementation methodology. The methodology is realised by so-called service modules that are explained in this section. Due to similarity of problems, such an implementation method is also relevant for other systems supporting process-oriented information management. 7.1 Challenges and Requirements in EnterprisesDuring the project various enterprises of different branches have been investigated regarding their requirements, challenges and initial situations for the implementation of the PreBIS system. The following aspects have been considered crucial for an implementation methodology by the participating users and consultants:
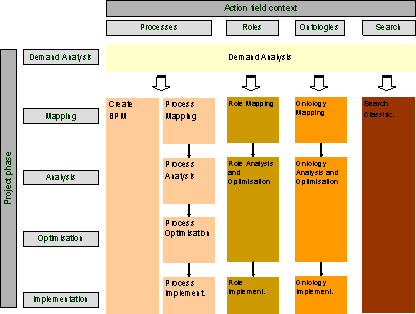
Considering these requirements when creating a methodology increases acceptance of work that needs to be completed during implementation. Therefore the methodology realises a portfolio of services for implementing PreBIS taking these requirements into account. Page 625 Because of its modular composition, the methodology is flexible enough to be adapted to the enterprise needs. Implementation efforts can be saved and it can serve as a guideline during an implementation project. The composition and configuration of the service portfolio are demonstrated in the example of services for context-extraction. 7.2 Modular Implementation ServicesThe working packages needed for the implementation should be structured systematically in order to coordinate single activities efficiently and to follow the identified requirements of enterprises. To systematise the implementation work, it is structured along two dimensions. It is first assigned to different action fields and then to the phases of the implementation project. Action fields that are relevant for PreBIS implementation are 'context', 'content', 'information technology' and 'project control'. Each action field is split up into subunits. The following action fields and subunits have been identified during the PreBIS project:
The second dimension consists of implementation phases. The following questions have to be answered in the phases by the service modules:
Page 2626 It will now be shown how service modules are integrated into this framework, using the example of the action field 'context'. A service module is defined here as a functionally autarkic unit that integrates activities which have to be accomplished by the PreBIS provider during an implementation project. The sum of all service modules describes the maximum extent of such a project. This concept of service modules is part of the discipline of Service Engineering (see [Böhmann and Krcmar (02)]). The action field 'context' contains all activities required for context extraction. The core question is: How can context information in the enterprise be made available to PreBIS? An overview of service modules, associated to action fields and phases is given in the following illustration:
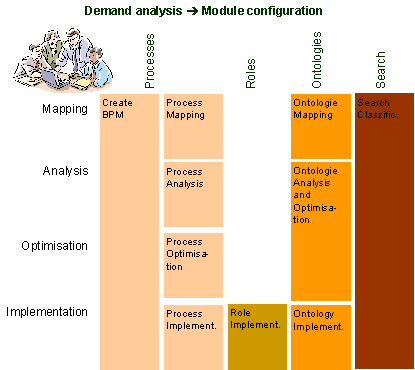
Figure 7: Service modules in the action field 'context' Work in this action field affects processes (Which processes are important for PreBIS?), roles (Which roles are important for PreBIS?), ontologies (Which term concepts are important for PreBIS?) and search classification (Which kinds of search proceedings are important for PreBIS?). In correspondence to the project phases described above, the service modules are assigned to one or more of them. Processes, for instance, need to be looked at in a more differentiated way because of their high complexity and importance in enterprises. Considering 'processes' as an example, the service modules are characterised as follows: The first service module at the process level is 'process mapping'. Its goal is to select those current business processes, which have to be supported by PreBIS, and capture them in a process model. Page 627 Information (process models) created in this module, is forwarded via an interface to 'process analysis'. Here, process models are analysed to uncover improvement potential (e.g. missing information for certain tasks or redundant tasks). Documented improvement potential serves as input for the service module 'process optimisation', were optimised process models are created considering improvement potential. Process models from mapping or optimisation phases present input for 'process implementation'. Now processes are made available for PreBIS (system import) and are also implemented into the organisation if they have been optimised before. All single context components (processes, roles, ontologies) are integrated into one model during this procedure (also see section 5.1 for details on this modelling approach). Beside this, the module 'Create BPM' (Business Process Management) is provided. The investigations of SMEs in the PreBIS project uncovered, that some of them do not have a process management yet. This is of importance because process oriented information or Knowledge Management needs an instance that designs, executes and controls processes that also underlie PreBIS. Accomplishing this service module therefore defines persons in charge and duties of such a process management. Furthermore, processes are selected, which shall be controlled in the future by the process management. To take this methodology as a guideline during an implementation project, each service module is also described by a process model that defines all steps that have to be taken to fulfil it. Apart from implementation phases, services for PreBIS operation can also be included into such a service portfolio. However, this contribution focuses on implementation services only. Building this methodology modularly facilitates the combination of those service modules that are needed according to the demand of a specific enterprise. This modular combination is referred to as module configuration. Within the scope of a demand analysis, the enterprise that wants to implement PreBIS is investigated regarding its previous works and goals. Both are drivers for module configuration. If, for instance, an enterprise has already documented its processes (previous work) and it does not wish to analyse or change them (goal), process mapping, analysis and optimisation do not need to be carried out. It has to be verified by the PreBIS provider/consultant at the end of the demand analysis if the process documentation of the enterprise is really appropriate for the implementation phase. Otherwise it might be necessary to accomplish the process mapping. Using such a modular approach, PreBIS can meet the expectations of SME, while at the same time saving a large amount of implementation effort. 7.3 Exemplary Application of the Introduction MethodologyThe introduced methodology for PreBIS implementation was evaluated in a workshop with a medium-sized enterprise. The goal of this workshop was to ensure applicability of the service modules. Therefore a demand analysis has been carried out to collect information about previous work in the enterprise and its goals to subsequently create a specific module configuration: Regarding processes, the enterprise has no process management. This, however, is considered crucial for future process maintenance. Furthermore, documentations of business processes exist but they are not up to date, not detailed enough, and only available for a few organisational units. In addition, the enterprise wants to remedy lacks in process documentation and process content. Page 628 After all, every service module of the process level was selected. In contrast to processes, the enterprise possesses extensive job descriptions, which have been developed just recently. Those can be taken as a base for the PreBIS role descriptions. Therefore, only the role implementation has to be proceeded. No previous works existed regarding ontologies. There are neither glossaries nor other documents available that describe the usage of certain terms in specific domains. Therefore ontology mapping is required. Beyond this the enterprise desires to analyse existing ontologies regarding optimisation potential for conceptual consolidation because they have experienced efficiency problems in term usage in the past. Almost no previous work existed in the field of search classification. Only a study about the usage of an internal archive system can be used to support separation of different search categories. Finally the service modules were configured as shown in figure 8. Implementation effort can be saved on the role level.
Figure 8: Module configuration resulting from a demand analysis in an exemplary SME-setting The estimation of the practical applicability in the exemplary application within the selected enterprise was positive. Especially its high customer orientation has been emphasized by the users. They recognized it as 'meaningful customizing' through modular composition. Furthermore, it was pointed out, that customers will be enabled to get adequate control in the implementation process. Above all this methodology is seen more as a holistic solution for one company's problems in the field of process oriented information management. Page 629 This is made possible by the autarkic benefit or use each service module provides, which exceeds the implementation of the PreBIS-system. Beside this the acceptance is also driven by transparency and comprehensibility of both single required tasks and the whole service portfolio. 8 Conclusion and OutlookThis contribution introduced the PreBIS project, which implements a business process oriented knowledge infrastructure with a focus on appropriate information provision and collaboration support at the level of organisational roles. The core of the solution is the implementation of an adaptive, dynamic information space that adjusts to the information demand of individual users and to the usage pattern of a role-oriented community over time. Such a pre-build information space can be constructed by combining modelling approaches from the ontology domain and from the business process domain and a phase model for a stepwise creation and refinement of the data structure. In order to reduce the entry barrier, especially for SME a combination with automatic analysis methods in the structure phase and the use of machine learning algorithms to adopt the information space during the usage phase is essential. It turned out, that the connection of an Information or Knowledge Management System with a process control system that executes a specified business process was a novel approach that could be successfully implemented. Still, the presence of an IT-system that controls the value creating knowledge intensive process cannot always be assumed. Leaner solutions are required that enable use of business process oriented knowledge infrastructure for small enterprises or weakly structured business processes with high variability and a low repetition rate. Since the prerequisites regarding the maturity of the business processes, existing knowledge management solutions and reusable information and structures vary in different enterprises a modular approach for the introduction of the PreBIS-System proved to be successful as it can be customized to the needs of the enterprise. In addition to the functional description, cost statements for each module could be helpful to estimate the investment in the new solution. Furthermore, the concept of a modular introduction methodology could be extended to operational services, such as optimisation of services, incorporation of new information sources etc. that could be used regularly or only when needed. Acknowledgements The PreBIS-project is a joint research cooperation between academic institutions and German companies. It is partly funded by the German Federal Ministry of Economics and Labour under Registration numbers 01 MD 215 to 219. Project partners are the Universities of Leipzig and Stuttgart, InTraCoM GmbH, ISA Information Systems GmbH, TeleZentrum Edelsfeld GmbH as well as the Fraunhofer IAO and the companies TextTech GmbH, Semtation GmbH and EMI-Applications GmbH as embedded partners. An earlier and shorter version of this paper was presented at the 4th International Conference on Knowledge Management (I-KNOW-04) in Graz on 1st July 2004 [Delp et. al. 04]. Page 630 References[Abecker et. al. (02)] Abecker, A.; Bernardi, A.; Maus, H.: "Potenziale der Geschäqftsprozess-orientierung für das Unternehmensgedächtnis"; Abecker, A.; Hinkelmann, K. Maus, H.; Müller, H. J.: "Geschäftsprozessorientiertes Wissensmanagement"; Springer, Heidelberg (2002), 215-248. [Biemann et. al. 04] Biemann, Chr.; Bordag, S.; Heyer, G.; Quasthoff, U.; Wolff, Chr.: "Language-independent Methods for Compiling Monolingual Lexical Data", Proc. Ci-cLING 2004, Seoul, Korea and Springer LNCS 2945, Springer, Heidelberg, (2004), 215-228. [Böhm, Härtwig 05] Böhm, K,; Härtwig, J.: "Prozessorientiertes Wissensmanagement durch kontextualisierte Informationsversorgung aus Geschäftsprozessen", Proc. WI-2005, Bamberg, Physica-Verlag, Heidelberg, (2005). [Böhm, Fähnrich 03] Böhm, K.; Fähnrich, K.-P.: "Rollen- und aufgabenorientiertes Wissensmanagement durch Geschäftsprozessorientierung", Beitrag zur KnowTech-2003, verfügbar unter www.knowtech.net, München, (2003). [Böhm et. al. 02] Böhm, K., Heyer, G., Quasthoff, U., Wolff, C.: "Topic Map Generation using Text Mining"; J.UCS (Journal of Universal Computer Science) 8, 6 (2002), 623-633. [Böhmann and Krcmar (02)] Böhmann, T.; Krcmar, H.: "Modulare Servicearchitekturen"; In: Bullinger, H.-J.; Scheer, A.-W. (eds.): "Service Engineering. Entwicklung und Gestaltung innovativer Dienstleitungen"; Springer, Berlin (2002). [Curbera et al. (03)] Curbera, F., Andrews, T., Dholakia, H. et al.: "Specification: Business Process Execution Language for Web Services Version 1.1", www-106.ibm.com, in /developerworks/webservices/library/ws-bpel, (2003). [Davenport, Völpel 02] Davenport, T. H.; Völpel, S.: "Introduction to basic concepts, project types, organisational structures an IT in Knowledge Management". In: Knowledge Management Case Studies: Project Expertises, Implementation Insights, Key Questions: Sukowski, O.; Eppler M., J. (Eds.). NetAcademy Press, St. Gallen (2002). [Delp, Engelbach 03] Delp, Martin; Engelbach, Wolf: "Kontextbezogene Informationsversorgung: An-wenderanforderungen und Granularität der Modellierung". In: "Leipziger Beiträge zur Informatik, Band 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003). [Delp et. al. 04] Delp, M.; Böhm, K.; Engelbach, W.: "Pre-Built Information Space: Some Observations on the Challenges of Process-oriented Knowledge Management". Proc. 4. I-KNOW, Springer Publishing, Graz (2004), 416-423. [Eberhardt et. al. 02] Eberhardt, C.-T.; Gurzki, T.; Hinderer, H.: "Media Vision Expert - Marktübersicht Portal Software. Marktübersicht für Business-, Enterprise-Portale und E-Collaboration." Fraunhofer IRB Verlag, Stuttgart (2002). [Elst et. al. 03] van Elst, L; Aschoff, R. F.; Bernardi, A; Maus, H.; Schwarz, S. : "Weakly-structured Workflows for Knowledge-intensive Tasks: An Experimental Evaluation." Proceedings of the WETICE 2003, IEEE Press (2003). [Engelbach, Delp 03] Engelbach, W.; Delp, M.: "Kontextbezogene Informationsversorgung: Anwenderanforderungen und Granularität der Modellierung"; In: "Leipziger Beiträge zur Informatik, Bd. 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 16-25. Page 631 [Engelbach, Delp 04] Engelbach, W., Delp, M.: "Einführungs- und Betriebsdienstleistungen für eine kontextbezogene Informationsversorgung"; Ockenfeld, Marlies (2004): Information Professional. Strategien - Allianzen - Netzwerke (2004), Proc. 26. Online-Tagung der DGI, (2004), 59-69. [Fähnrich, Böhm 03] Fähnrich, K.-P., Böhm, K.: Rollen- und aufgabenzentriertes Wissensmanagement . In: Forschungs- und Technologiemanagement, Dieter Spath (Hrsg.). Hanser, München, Wien, (2003), 189-194. [Flor 04] Flor, T.: "Experiences with Adaptive User and Learning Models in eLearning Systems for Higher Education" In: Journal of Universal Computer Science, volume 10 (2004), issue 1, 58-72. [Fillies et. al. 01] Fillies, C.; Wood-Albrecht, G.; Weichardt, F.: "A pragmatic application of the semantic web using SemTalk", Proc. 11th-international conference on World Wide Web, Honolulu, Hawaii, USA, (2001). [Fillies et. al. 03] Filles, C.; Quasthoff, U.; Schaar, A.; Schmidt, F.: "Werkzeugunterstützte Modellierung von kontextuellen Informationsräumen"; In: "Leipziger Beiträge zur Informatik, Bd. 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 64-71. [Gronau, Weber 04] Gronau, N.; Weber, E.: "Defining an infrastructure for knowledge intensive business processes", Proc. 4. I-KNOW, Springer Publishing, Graz (2004), 424-431. [Gurzki, Özkan 2003] Gurzki, T.; Özkan, N.: "Unternehmensportale: Kunden-, Lieferanten- und Mitarbeiterportale in der betrieblichen Anwendung". IRB-Verlag, Stuttgart: (2003). [Habermann 01] Habermann, F.: "Management von Geschäftsprozesswissen: IT-basierte Systeme und Architektur".: Dt. Univ.-Verl., Wiesbaden (2001). [Härtwig, Fähnrich 03] Härtwig, J.; Fähnrich, K.-P.: "Grundkonzepte des Wissensmanagement im Informationsraum"; In: "Leipziger Beiträge zur Informatik, Band 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 35-42. [Hoof et. al. 03] Hoof, van A.; Fillies, C.; Härtwig, J. : "Aufgaben- und rollengerechte Informationsversorgung durch vorgebaute Informationsräume"; In: "Leipziger Beiträge zur Informatik, Band 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 1-9. [Hofer-Alfeis 02] Hofer-Alfeis, J., Spek, van der, R.: "The Knowledge Strategy Process - an instrument for business owners". In: Knowledge Management Case Book, Davenport, T., Probst, G. J. B. (Eds.), Publics KommunikationsAgentur, Erlangen (2002). [Holz et. al 03] Holz, H.; Melnik, G.; Schaaf, M.: "Knowledge Management for Distributed Agile Processes: Models, Techniques, and Infrastructure", Proceedings IEEE International Workshops on Enabling Technologies: "Infrastructure for Collaborative Enterprises (WETICE) 2003", IEEE Computer Society, Linz (2003). [Hoyer 88] Hoyer, R.: "Organisatorische Voraussetzungen der Büroautomation: Rechnergestützte, prozessorientierte Planung von Büroinformations- und Kommunikationssystemen", Erich Schmidt Verlag, Berlin (1988). [Kamphusmann 01] Kamphusmann, T.: "Anwendungen für Wissensarbeiter. Inhaltsbezogene Recherche und Informationsangebote". In: Deiters, W.; Lienemann, C. (Hrsg.): "Report Informationslogistik - Informationen just-in-time". Symposion Publishing, Düsseldorf, (2001), 82-93. Page 632 [Krallmann et. al. 02] Krallmann, H.; Frank, H. F.; Gronau N.: "Systemanalyse im Unternehmen", Oldenbourg, München (2002). [Mertins et. al. 03] Mertins, K.; Heisig, P.; Alwert, K.: "Process-oriented Knowledge Structuring"; Journal of Universal Computer Science 9, Heft 6 (2003), 542-550. [Ngonga, Fähnrich 03] Ngonga Ngomgo, A.-C.; Fähnrich, K.-P.: "Der Informationsraum als Metapher für die Realisierung dynamischer Informationsbedürfnisse im Kontext rollenbasierter Communities". In: "Leipziger Beiträge zur Informatik, Band 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 26-34. [Probst et. al. (03)] Probst, G. J. B; Raub, S.; Romhardt, K.; "Wissen managen" ; Gabler, Wiesbaden (2003). [Remus 02] Remus, U.: "Prozeßorientiertes Wissensmanagement. Konzepte und Modellierung"; Universität Regensburg: Dissertation (2002). [Schmidt, Winterhalter 04] Schmidt, A.; Winterhalter, C.:"User Context Aware Delivery of E-Learning Material: Approach and Architecture", J.UCS, Volume 10, Issue 1, 38-46. [Schomisch, Hoffmann 04] Schomisch, M.; Hoffmann, M.: "Wissensmanagement in der Praxis der Unternehmensberatung - Wie das Knowledge Center der Detecon mit MERLIN die Berater-Performance erhöht". In: Gronau, N., Petkoff, B., Schildhaur, T. (ed.): "Wissensmanagement - Wandel, Wertschöpfung, Wachstum"; GITO, Berlin (2004), 129-136. [Schütt 04] Schütt, P.: "Die Wissenstransformation eines Unternehmens - am Beispiel IBM". In: Gronau, N., Petkoff, B., Schildhaur, T. (ed.): "Wissensmanagement - Wandel, Wertschöpfung, Wachstum"; GITO, Berlin (2004), 29-36. [Staab et. al. 01] Staab, S.; Schnurr, H.-P.; Studer, R.; Sure, Y: "Knowledge Processes and Ontologies", In IEEE Intelligent Systems 16(1), January/February 2001, "Special Issue on Knowledge Management" (2001). [Süßmilch-Walther 03] Süßmilch-Walther, I.: "Situative und personalisierte Rollen- und Unternehmensmodellierung". In: "Kolloquium für Doktoranden der Wirtschaftsinformatik"; 6. Internationale Tagung Wirtschaftsinformatik, Wilthen (2003). [Wyssusek 01] Wyssusek, B. (2001): "Kommunikationsstrukturanalyse." In: Mertens, P. et al. (Hrsg.): "Lexikon der Wirtschaftsinformatik", Springer, Berlin et al., S. 269 f. [Zagos, Kiehne 03] Zagos, A., Kiehne, D.-O.: "Wirtschaftliche Perspektiven, Anwendungen und Chancen für das Prozessorientierte Wissensmanagement"; In: "Leipziger Beiträge zur Informatik, Bd. 1", Fähnrich, K.-P.; Herre, H. (Eds.). Universität Leipzig, Leipzig (2003), 10-15. Page 633 |
|||||||||||||||||