| Submission Procedure |
Analysis, Design, and Performance Evaluation of MS-RTCP: More Scalable Scheme for the Real-Time Control ProtocolN. A. Elramly, A. S. Habib, O. S. Essa H. M. Harb Abstract: Recently, some problems related to the use of the Real-time Control Protocol (RTCP) in very large dynamic groups have arisen. Some of these problems are: feedback delay, increasing storage state at every member, and ineffective RTCP bandwidth usage, especially for the receivers that obtain incoming RTCP reports through low bandwidth links. More schemes are proposed to alleviate the RTCP problems. The famous and recent one, which was introduced by EL-Marakby and was named Scalable RTCP (S-RTCP), still has several drawbacks. This paper will evaluate the previous model by introducing all its drawbacks. Consequently, we will demonstrate a design of More Scalable RTCP (MS-RTCP) scheme based on hierarchical structure, distributed management, and EL-Marakby scheme. Also, we will show how our scheme will alleviate all the drawbacks found in the S-RTCP. Finally, we will introduce our scheme implementation to analyze and evaluate its performance. Keywords: RTCP Scalability, Distributed Management, Multimedia Protocols, Multimedia Communication Category: C.2.2, C.2.6 1 IntroductionToday, the Real-time Transport Protocol (RTP) is widely deployed in most Multicast Backbone (MBone) applications over the Internet involving multiple senders and receivers. The RTCP, which is RTP's control protocol, is used mainly in adaptive applications where the sender changes its rate of data transmission in order to suit current state of the network [1]. Some problems have arisen when RTCP has been used in very large dynamic multicast groups [2]. Firstly, because the RTCP reporting interval grows linearly with the group size, a feedback delay occurs. Consequently, infrequent feedback reports are sent and timely reporting does not occur. Second, each member has to keep track of every other members in the group, thus a storage scalability problem may appear [3]. Third, a flood of initial RTCP reports multicast to the whole group can occur when large number of members joins at the same time. Page 874 As a result, members can be flooded with these reports, especially the ones connected to the network through low bandwidth links, and the network may be congested [4]. This problem occurs if the reporting members are not implementing the reconsideration algorithms that are described in [2], [3]. Fourth, for receivers connected through low bandwidth links, the RTCP bandwidth available could be used more effectively than is presently the case. More models have been appeared to alleviate the RTCP problems [2], [3]. The recent one is proposed by El_Marakby [5]. This model is based on hierarchical scheme, whose group members are organized in local regions. Members in each region send their Receiver Reports (RRs1) [1] locally to an Aggregator (AG2) [5] in the same region. The AG summarizes important information in the RRs and derives some statistics, then sends its information to the manager. The manager does some monitoring and diagnosis functions to estimate which regions are highly suffering form congestion and to evaluate the quality of the transmitted data [5]. This paper proceeds as follows: In Section 2, some background information about El_Marakby scheme and its evaluation are presented. Section 3 describes the MS-RTCP. Section 4 presents how our scheme solves El_Marakby scheme problems. In section 5, analysis and performance of the MS-RTCP are introduced. Finally, we summarize the current status and outline future work. 2 El_Marakby Scheme and its EvaluationThe basic idea of El_Marakby scheme is to develop a tree-based hierarchy of report summarizers. At the lowest level of the tree, session participants send RRs. A node, acting as an AG, collects these reports, and summarizes them. These summaries are then passed up towards the next highest node in the tree, until finally they reach the sender or some other appropriate feedback point. The summarization scheme is most useful when the nodes at one level of a sub-tree see similar network performance. El-Marakby uses network hop counts to a summarizer, measured through Time To Live (TTL3), to group hosts together in the tree. She also proposed a dynamic scheme for building the tree [5]. The summarizer approach appears to be quite attractive; the hierarchical nature of the system allows for scalability, less information would need to be maintained at any given node, and convergence times would be reduced. However, the scheme has a number of drawbacks for Internet Protocol (IP) telephony and management basics:
1 RR is a report for reception statistics from participants that are not active senders. 2 AG is an expression used in the S-RTCP, and acts as a manager. It summarizes the reports sent by its children. 3 TTL specifies how long, in seconds, the packet is allowed to remain in the Internet system. 4 Children are the session participants. Page 875 3 MS-RTCPRTCP scalability problems are due to the dynamic increase of the group size on the fixed low bandwidth. The RTCP scalability problems don't appear on the small RTP session. So the solution idea for all RTCP scalability problems will be based on how to transform the large group into small groups. This can be achieved by transformation of the RTP session to tree graph taking in consideration some factors that are important to be present, like:
To satisfy these features, we should build another scheme called MS-RTCP. The MS-RTCP has nine components, all of them are control entities except the managers and the children support for data and control functions. Each of which is responsible for one or more of the management tasks. These components are working in harmony to raise the quality of the scheme (for the details of each MS-RTCP component functions, see Appendix A.1). We will describe the MS-RTCP by demonstrating the following subsections:
5AGR is an expression used in the S-RTCP. It indicates the summarized message sent to the system administrator by the AG. 6LAG is a component that acts as a manager in relation to local area network. 7SDES is a source description items that contains some personal data about RTCP packet originator. Page 876 3.1 How does the MS-RTCP work?When starting the RTP session, two multicast addresses are announced; the first address is for the delivery of RTP data packets, while the second one is for transporting RTCP control packets. Then, the MS-RTCP managers join the control multicast group, while the MS-RTCP children join the data multicast group. Each group of children constructs a region which is controlled by a manager. Each child should know its region before sharing the RTP session. The Load Balancing Manager (LBM) accomplishes this target by testing the real position of each child and the real number of children per region. In MS-RTCP, each shared child should possess two addresses; the IP address referring to the child Internet position, and the tree address referring to the position of the child in the MS-RTCP. After the child finds its region, the Address Resolution Manager (ARM) will take the child IP address and will provide this child with its tree address. At any time, if the child is turned to a manager, the Fault Tolerance Manager (FTM) should find a spare component for this new manager. The scheme has to collect the personal data about any one sharing the RTP session. So, our scheme should contain a manager to store this personal data in its database. The RTP session participants personal data is collected by SDES Manager (SDES-M). After each child is settled in its region, it will send RRs to its region manager. Thereafter, the manager collects the different RRs and summarizes them using any analytic function(s). Hence, the manager can extract a report and send it to the General Manager (GM) (or the up-level managers in the MS-RTCP). The GM collects all the managers' reports and evaluates the RTP session performance. For data persistency and fault tolerance considerations, all stored data should be saved in a spare copy. The Collection Database Manager (CDM) is responsible for connecting any scheme managers and taking a copy of the stored data (For more details, see Appendices A.2 and A.4. For the communication form, see Fig. A.5). 3.2 Handling of the multiple sender caseThe multiple sender case is described as follows. More than one sender can send its Sender Report (SR8) [1] simultaneously to one child or more in the RTP session. To handle the multiple sender case, we will demonstrate 4 algorithms, each algorithm responsible for one sub-process. These algorithms are running sequentially because each one works after the result of the previous algorithm. The result extracted from the last algorithm could be considered as a packet that will be sent from any manager to another up-level manager or GM in the management tree. The basic idea of multiple sender algorithms is built on how to analyze and filter the data for each stand-alone sender. Consequently, this sender data will be parsed by some management functions. Accordingly, the manager can extract the locations of the problems and send a report to the GM. The first algorithm is responsible for collecting the Synchronization Source (SSRC9) identifier [1] of all senders in the RTP session. Also, the duplicated SSRCs are eliminated by using the first algorithm. So, we can extract and distinguish the senders from other children.
8SR is a report for transmission and reception statistics from participants that are active senders. 9SSRC is a field used in the RTCP different packets' header to identify the packet originator. Page 877 The second algorithm uses the extracted SSRCs to collect the different reports. These reports contain all the data that are important for each manager to evaluate its region senders. It is obvious that the result of the second algorithm is in form of different reports from different senders. Till now, the overview of the collected reports is not suitable for the manager to evaluate each sender individually. So, the data of each sender should be filtered such that the manager can view and summarize all the individual sender reports. The third algorithm can separate the reports of each sender using the extracted sender's SSRC [7]. Now the data becomes ready for the manager to analyze it. The forth algorithm will provide the manager with some diagnostic functions (like Average, Median, and Standard Deviation (SD)) to help him with the analysis operations (for the algorithms' steps, see Appendix A.3). 4 How did MS-RTCP Solve the El_Marakby Scheme Drawbacks?
Remark: GM determines if a new child is a manager or ordinary child using the same technique of El_Marakby scheme [5]. 5 Implementation and Simulation Results for MS-RTCP5.1 Simulation setupThereafter, we will implement the system to demonstrate how the MS-RTCP alleviated the three RTCP problems [2], [4] similar to the S-RTCP scheme. Unlike the S-RTCP, the MS-RTCP can adapt the system management and guarantee the fault tolerance, scalability, and load balancing between the MS-RTCP components. The implementation includes also the effects of our scheme uploaded components (FTM, LBM,...) on performance and scalability of the system. In our analysis we will use a network simulator called NS2 [8] that works with the following characteristics:
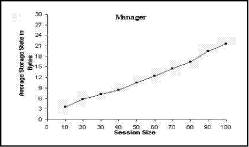
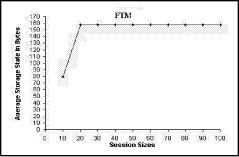
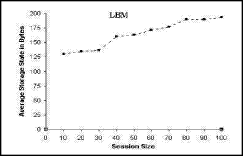
In the following subsections, we will demonstrate the implementation results in relation to each RTCP problem. Concerning with scalability, our implementation will comprise a comparison between S-RTCP and MS-RTCP. 5.2 Storage state evaluationIf any manager in the scheme is overloaded with data (exceeding its capacity), new parameters (time of search and data persistency) will develop and should be taken in consideration. So the storage state should be tested for each control component in the MS-RTCP. Page 879 Figure 1: Average storage state of the Manager. In the MS-RTCP, it is obvious that each manager stores all its own children SSRC only. Consequently, the number of stored bytes depends on the SSRC unit capacity. Each manager is responsible for approximately the same number of children. Hence, the increase in the session size is accompanied by an increase in the manager storage area. In Fig. 1, the simple oscillation found in the curve resulted from the slight variability in the number of children in each region. This curve also demonstrates the efficiency of LBM to keep a balanced managers' load. Figure 2: Average storage state of the FTM. The session containing approximately 10 children is considered a simple session. The simple session contains only one manager. Hence, the FTM stores a little data about this manager and its spare one. When the session accepts more children, the regions will be constructed and the number of managers will increase. Consequently, the FTM will store more data to define all the session managers and their spares. Therefore, the stability in the curve, which is found in Fig. 2, results from the fixed number of the managers when the session size is between 20 and 100 children. Page 880
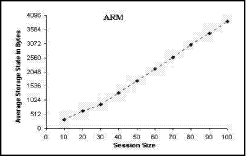
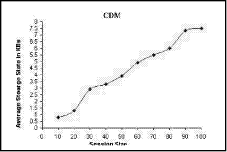
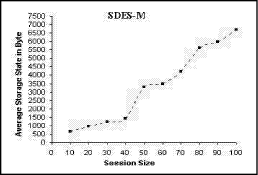
Figure 3: Average storage state of the ARM. Fig. 3 explains the ARM storage state in bytes. The ARM storage area is increased following an increase in the session size. The subsequent increase in the ARM storage area is justified by the fact thatq the ARM is responsible for storing the IP and tree addresses for all the MS-RTCP components. We can notice a minimal oscillation in the curve when the session size is between 10 and 30 children. The minimal oscillation occurs since we have supposed that the session size is dynamic, i.e. more children are joining or leaving the session suddenly during a small time interval. When the session size exceeds 30 children, the sudden change in the session size doesn't occur, and the curve becomes smooth (the oscillation disappears). Figure 4: Average storage state of the CDM. The CDM storage area is increased following an increase in the session size. The increase in the CDM storage area is concerned with storing the CDM for the IP and tree addresses about each MS-RTCP component. In Fig. 4, the notable oscillations are due to rapid joining and leaving the RTP session by a group of children, i.e. a group of children stays in the session for a short time interval without any active sharing. The LBM stores the maximum and real numbers of each region together with the tree address of each manager in the session. Therefore, the storage area is approximately constant while the session size is increasing. In Fig. 5, the oscillations found in the curve are due to gradual creation of regions. While a new region is being created, a little data is added to the LBM database. Page 881 Figure 5: Average storage state of the LBM. It was formerly documented that the main function of the SDES-M is to store the personal data about each child sharing the RTP session. So, if the number of children increases, the SDES-M stored data will increase consequently. In Fig. 6, the oscillations found in the curve results from the sudden changes in the session size.
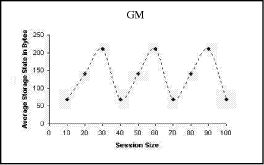
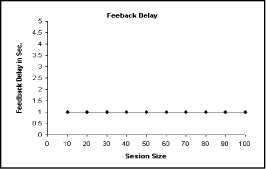
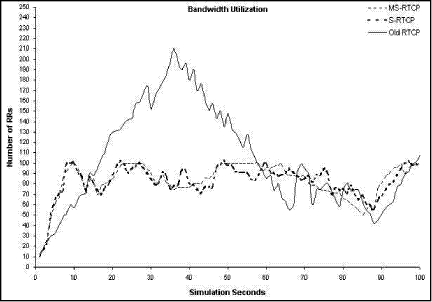
Figure 6: Average Storage State of the SDES-M. Figure 7: Average storage state of the GM. The GM stores the processed data for a period of time to compare such data with another data collected during the subsequent periods. Page 882 The time taken by the GM to keep the summarized data depends on two parameters: 1) The GM properties which determine its storage capacity. 2) The session size which determines the quantity of data that will be summarized and sent to the GM. In our simulation, the GM can store the evaluated data that coming from under-level managers for 30 seconds, then delete it. The deletion of the data is followed by instantaneous resorting of another evaluation data. The process of storage, deletion, and restoring are occurred consequently. These consequent operations cause the big oscillations in the curve presented in Fig. 7. 5.3 Feedback delay evaluationFig. 8 shows the average feedback delay, i.e. the average time interval between two consecutive feedback reports. It is obvious that the feedback delay is constant (one second) in the MS-RTCP. As the children are divided into regions, the feedback delay is calculated depending on the region size (approximately equal at all regions) and regardless the session size. Figure 8: Feedback delay between two consecutive RRs for each user. 5.4 Bandwidth utilization evaluationTo analyze our scheme in relation to the bandwidth utilization, we should determine the average number of feedback RRs which are sent during the simulation time. If the number of RRs increases with notable values during any time interval, this may lead to decrease the bandwidth for the multimedia data. Consequently, the congestion problem probably occurs. In Fig. 9 it is obvious that the number of RRs sent in the MS-RTCP and the S-RTP is approximately equal. Also, it is notable that the number of RRs sent in the old RTCP is large between 25s and 55s. In the old RTCP scheme, large number of RRs occurs because the whole RTP session can be considered as one region. Page 883 Figure 9: Bandwidth utilization in MS-RTCP, S-RTCP, and RTCP Also, in the MS-RTCP curve, it is obvious that the number of RRs during the time interval 80s-90s decreases significantly. The significant decrease in the RRs is justified by the event that a large number of old children left the session and new children were gradually joining to the session. 5.5 Comparison of the S-RTCP and the MS-RTCP in relation to scalabilityIn this subsection, we will study the scalability of the MS-RTCP and the S-RTCP. To accomplish this scalability study, a session size should be increased up to 1000 children. This number of children makes our test more accurate. To demonstrate the attitude of the MS-RTCP and the S-RTCP while the session size is increasing both gradually and suddenly, two tests must be performed:
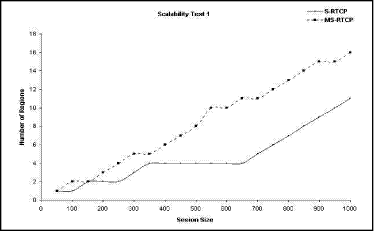
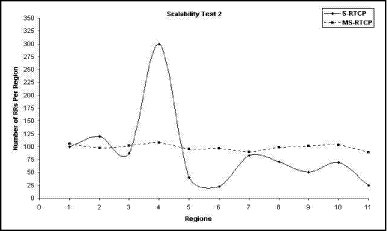
The plot, which can be seen in Fig. 10, shows the comparison between the S-RTCP and the MS-RTCP as regards to the children distribution among the regions. In the S-RTCP curve, at the session size between 350 and 650 children, it is obvious that the curve is stable. The curve stability means that any new child hich joins the session will settle in the old four regions. Also, we can notice that about 7 regions are created when the session size is between 650 and 1000. This indicates that the distribution of children in the regions is abnormal, and a notable diversion will be found in the managers' load. Unlike S-RTCP, the MS-RTCP has a normal curve with minimal oscillations. When the MS-RTCP session size increases (gradually or suddenly), new regions are created. This curve also demonstrates the efficiency of the LBM in children distribution over the regions. Page 884 We can also observe that the number of the regions in the MS-RTCP is more than in the S-RTCP. This is because the LBM tests the real number of children per region every time. When the LBM finds a notable increase in a region size, it stops the children entry in this region, and creates a new one. Figure 10: Scalability test (distribution of children among the regions). The plot found in Fig. 11 determines the number of RRs that are sent to each S-RTCP region and MS-RTCP region. In the S-RTCP curve, we can notice that the number of RRs sent to the region number 4 is large. This results from the abnormal distribution of children which makes the region number 4 overloaded. An important notice must be taken in our consideration viz.: if there is a notable increase in the session size (e.g. thousands), the S-RTCP system administrator has only two possibilitz to deal with this situation. The first possibility is to reject the joining of extra children when the region size reaches its maximum, and this is against the scalability definition. The second possibility is to increase the maximum size that each region can load. This second possibility may lead us to the first case of the RTCP (huge number of children with one manager) with its three problems. In the MS-RTCP curve, it is observed that the number of RRs in each region is approximated due to the LBM efficiency. Page 885 Figure 11: Scalability test 2 (average number of RRs in each region). 6 ConclusionWe have presented the problems encountered in the deployment of RTCP in large dynamic group. Also, we have introduced a brief discussion of the previous RTCP scalability scheme (El_Marakby) and its drawbacks. We have designed a more scalable scheme for RTCP called MS-RTCP, in which members are organized dynamically in local regions. Every region has a basic manager and a spare one. The manager monitors its region and sends the result to the up-level manager. At the end, the GM receives the data from the under-level managers, which represent the evaluation of the whole network (session). The basic idea of our scheme is built on the management distribution. So, we have a manager for each essential management function. Also, we have introduced how our scheme overcame all the previous scheme drawbacks to be more scalable. Finally, we have evaluated the MS-RTCP performance in relation to all RTCP problems and system scalability by using a network simulator called NS2. 7 Future WorkThe next phase of our work is divided into two approaches:
Page 886 Acknowledgements We would like to express our deep thanks to the people who have helped during the research preparation. Also, we greatly indebted and grateful to the Professor Mohamed M. El-kafrawy, for his efforts, advice, and continuous encouragement. References[1] H. Schulzrinne, S. Casner, R. Frederick, and V. Jacobson, "RTP: A Transport Protocol for Real-Time Applications," IETF Internet Draft, March 2, 2003. [2] J. Rosenberg and H. Schulzrinne, "Timer reconsideration for enhanced RTP scalability," Proceeding of the Conference on Computer Communication (IEEE Infocom), San Francisco, California, March/April. 1997. [3] J. Rosenberg and H. Schulzrinne, "Sampling of the group membership in RTP," IETF Request for Comments 2762, Feb. 2000. [4] B. Aboba, "Alternative for enhancing RTP scalability," IETF Internet Draft, Jan. 1997. [5] R. El-Marakby and D. Hutchison, "A scalability scheme for the real-time control protocol," Proceeding of IFIP Conference on High Performance Networking (HPN'98), Vienna, Austria, Sept. 1998. [6] R. El-Marakby and D. Hutchison, "Design and performance of a scalable real-time control protocol simulations and evaluations," Proceeding of IFIP Conference on High Performance Networking (HPN'98), Vienna, Austria, Sept. 2000. [7] Y. Langsam, J. Augenstein, M. Tenenbaum, J. Mushe " Data Structures Using C and C++ (2nd Edition)" Prentice Hall, Upper Saddle River NJ, USA. 1996. [8] S. McCanne and Floyd, (McCanne, 1998) "LBNL Network Simulator," 2003 version, 2003. Page 887 List of Abbreviations
Page 888 AG Aggregator. AGR Aggregator Report. ARM Address Resolution Manager. Appendix ADetails of the Protocol from the Implementation ProspectiveA.1 MS-RTCP components' functionsA.1.1 Manager (Tree address depends on its location)
It collects and parses the information received from the children (RRs), then performs the following functions:
Remark: If the region manager cannot reach the sender, it sends a message to the direct up-level managers and so on, till it has reached the sender. A.1.2 FTM (Tree address = 1) This manager is responsible for defining a spare component for each scheme component. So if any trouble has occurred in any component, the GM consults the FTM to extract the spare component of the failed one. The fields which are used by FTM are: 1) Basic manager address: the address of each scheme manager in the normal state (no problem state). 2) Spare manager address: the address of the manager which should substitute the failed manager (each component in the MS-RTCP have a spare one except the session children. We explained the manager as an example). A.1.3 LBM (Tree address = 2) This manager is responsible for load adjustment between managers in the MS-RTCP by storing a real number of children per region. When a new child tries to join the RTP session, the LBM takes into consideration not only the maximum number of children but also the real children number. The fields which are used by LBM are: 1) Basic manager address: the same address stored in the FTM. 2) The maximum number of children: the number of children that the manager can load without exceeding this number. 3) The real number of children: the number of children which the manager has loaded at each interval. Page 889 A.1.4 ARM (Tree address = 3) This manager is responsible for storing the tree address (the address which indicates the component real location in the management tree) of any MS-RTCP component. This tree address corresponds to the IP address of the component. The fields which are used by ARM are: 1) Component IP address. 2) Tree address. A.1.5 SDES-M (Tree address = 4) This manager is responsible for defining all the data about the RTP session participants like name, address, geographical location, e-mail,....etc. A.1.6 CDM (Tree address = 5) This manager is responsible for storing all the management data which is stored by all the scheme managers (can be considered as a data spare copy). A.1.7 Children (Tree address depends on its location) Children are RTP session participants that send SRs or RRs. A.1.8 LAN-M LAN-M executes the same functions and collects the same data as a pre-explained manager but from a Local Area Network (LAN). A.1.9 GM (Tree address =0)
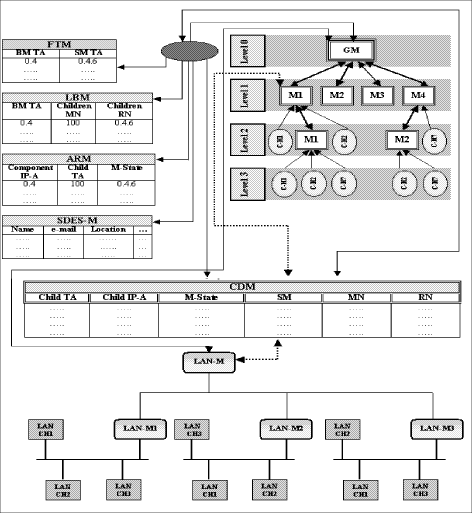
Remark: The general view of our scheme that describes the communications of the scheme components is shown in Fig. A.5. Page 890 A.2 Details of the MS-RTCP work ideaIn this subsection, we will describe how the model works by demonstrating the following:
A.2.1 How can a new child join the RTP session? When a new child connects to the RTP session, the following steps are executed:
A.2.2 How can an old child leave the RTP session? When an old child leaves the RTP session, the following steps are executed:
A.2.3 The basic relations between the GM and other model entities
10BY is RTCP packet indicates end of participation
Page 891 A.2.4 The basic relations between the Manager (or LAN-M) and other model entities
A.3 Multiple sender case algorithmsIn the next subsections, we will demonstrate a prototype for the variables which should be used in our algorithms. Thereafter, we will introduce our algorithms according to the processes arrangement. A.3.1 Prototype We define some dynamic arrays as follows:
Remark: N_RR and M_SSRC can be counted by any counter variable in the manager code. A.3.2 Algorithms Algorithm 1 extracts all the SSRCs for the senders in the RTP session. This can be accomplished by accurate scanning for each sender report using For loop. Consequently, the algorithm keeps the extracted SSRCs in stand-alone array. The array resulted from algorithm 1 is called SSRC_Array. To extract the individual source identification for each sender in the RTP session, algorithm 1 will delete the duplicated SSRCs that may be found. A. Algorithm 1 (SSRCs Extraction Algorithm) 1- For I= 1 to N_RR
Page 892 By using the SSRCs resulted from algorithm 1, we can scan the RRs and extract the data of the session senders. Algorithm 2 can achieve this target by comparing the SSRC_Array entries with the SSRCs of the reports. If they are equal, the algorithm keeps the data of the scanned reports, and if not, these reports will be neglected. B. Algorithm 2 (Data Extraction Algorithm) 1- For K=
1 to H_Sender Now, after running algorithm 2, we have an array of structures called SSRC_Final, where each structure in this array represents a total report for a specific sender in the manager region. Consequently, we can extract any summarized data for any sender by running two above algorithms. Each manager in the system can accept more than one array as SSRC_Final that is taken from the under-level managers or from the children in its region. So, we should filter the data for each sender, but till now, we have different arrays' structures. Algorithm 3 will be introduced to accomplish this process. C. Algorithm 3 (Separation Algorithm)
Page 893 After each sender data which is found in MLA is filtered, we can parse it and extract the problems by applying some diagnostic functions. Running algorithm 4 can perform this target. D. Algorithm 4 (Diagnostic Algorithm)
A.4 Scheme messages (types and structure) Some of new messages are added to our new scheme for connecting the scheme components with each other. Scheme messages should be defined according to both type (who send or receive it) and structure. A.4.1 Types of the MS-RTCP Messages.
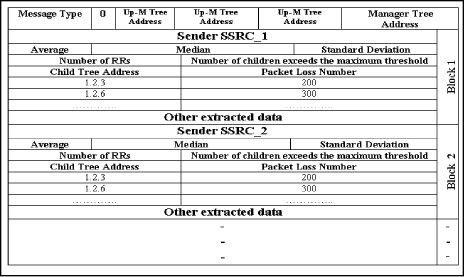
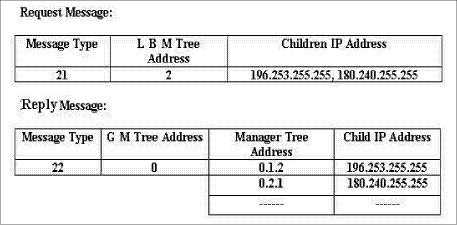
A.4.2 Structure of the MS-RTCP Messages. 1- Message from Manager to Manager (or GM) in the RTP Session (Message Type = 0) All fields of this message are previously stated above. The output of running above four algorithms is the Manager-to-Manager message, Fig. A.1. Page 894 Figure A.1: Manager (or GM)-to-Manager message 2- Fault tolerance message from GM to FTM. (Request and Reply) (Message Type = 1) This message supports the relation between the GM and the FTM. When any problem occurs related to any scheme component, this relation between GM and FTM will be fired to solve this problem. This relation is accomplished by two different messages (request and reply). Request message contains four fields, viz. 1) Message type: 16-bit integer number to define the type of the message (for the request message = 11). 2) FTM tree address. 3) Basic manager tree address 4) State: If the manager crashed or left the RTP session. Reply message contains four fields also that can be stated as follows: 1) Message type (for the reply message = 12). 2) GM tree address 3) Basic manager tree address. 4) Spare manager tree address, Fig. A.2. Figure A.2: GM to FTM message Page 895 3- Load balancing message from GM to LBM (Request and Reply) (Message Type = 2) This message supports the relation between the GM and the LBM to adjust the number of children for each scheme manager. This relation includes request and reply message. The request message contains three basic fields 1) Message type (equal 21). 2) LBM tree address. 3) IP address for the new children. The reply message contains four basic fields, 1) Message type (equal 22). 2) GM tree address. 3) Manager tree address. 4) IP addresses for the children which are related to the manager in the previous field, Fig. A.3.
Figure A.3: GM to LBM message 4- Address resolution message (Message Type = 3) This message supports the relation between the GM and the ARM. It is sent from the GM to the ARM after a new child joins the RTP session informing it about the child tree address. This message contains five fields, 1) Message type. 2) ARM tree address. 3) Child IP address. 4) Child tree address 5) Manager state: determines if the new child is a manager (field value = M) or not, Fig. A.4.
Figure A.4: GM to ARM message The request and reply messages between GM and SDES-M have the same structure of the FTM messages but with different required fields (name, location,--------- ). Page 896 Figure A.5: General View of our scheme
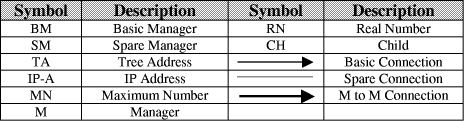
Table A.1: The Symbols that are used in the scheme general view Page 897 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||