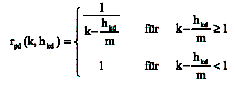| Submission Procedure |
Integration of Communities into Process-Oriented StructuresAndré Köhler Frank Fuchs-Kittowski Abstract: This article aims at the integration of communities of practice into work processes. Linear structures are often inappropriate for the execution of knowledge intensive tasks and work processes. The latter are characterized by non-linear sequences and dynamic, social interaction. But for the work in communities of practice the leading path, that is needed for structuring the work, is often missing. Our article exposes the requirements in order to integrate the dynamic, social processes of the knowledge generation in communities of practice with formal described knowledge intensive processes. For the support of communities the Wiki-concept is introduced. In order to integrate communities into process structures a concept for an appropriate interface is presented. On the basis of this interface concept an information retrieval algorithm is used to connect the process-oriented structures with community-oriented structures. The prototype realisation of this concept is shown by a short example. Keywords: cooperative knowledge generation, knowledge community, knowledge-intensive processes, process-oriented knowledge structures, Wiki Categories: H.3.3, H.3.5, H.5.3, H.5.4 1 IntroductionThe knowledge to handle concrete, practical tasks in the work process often exists already in IT systems, e.g. codified in information systems, documents and community applications. This knowledge which is existent in the company should be transparent and available throughout the organisation. The existing knowledge must be made available according to a collectively accepted and work process-oriented knowledge structure. For this purpose process structures are suitable in particular, because it is easier to establish a relationship between the own work process and the available knowledge carriers (e.g. persons, documents etc.). Thus, knowledge carriers that are relevant to work processes or to specific activities can be found and used easier. Technologies and tools of the process-oriented knowledge management can provide support for such a structured supply of knowledge. An example for such a tool is the APO-Pilot [Fuchs-Kittowski, 03a]. In knowledge-intensive work processes it can be necessary to develop new knowledge ad hoc and in cooperation with other people. Therefore the so far available IT solutions of the knowledge management are not adequate. These IT solutions make the already familiar knowledge, e.g. in form of documents, along inflexible knowledge structures (ontologies) available relating to the context. Page 410 Knowledge intensive tasks respectively knowledge generation processes are nonlinear, dynamic and socially imbedded [Brown, 89]. Especially the workflow of the processes as well as the required knowledge cannot be determined and made available completely in advance. In contrast, communities support communication that is essential for the exchange of knowledge and experiences. Communities allow thus processes for the cooperative knowledge generation and for the solving of problems. But knowledge, which is generated in and explained through communities is often characterised through a chaotic structure, an enormous size and fast growth. A technical support of communities must cope with the challenge to make a context-based access possible to the explained knowledge of the community. In this paper a concept to support the cooperative knowledge generation in communities in knowledge-intensive work processes and a tool, which is based on this concept will be presented. The central idea is the integration of communities with process-oriented knowledge structures. Therefore a community support was designed which refers to the work cycle as a context. Furthermore, it is oriented on the tasks and problems that can occur there. On the one hand, technology supports the context-based access to the knowledge of the community. On the other hand, it supports the flexible generation and conservation of new knowledge and experiences in the community alongside knowledge structures. The weakness of today's community applications, at which a context-based access to the chaotic generated knowledge is not possible, will be overcome. Furthermore, the weakness of knowledge management systems, which are not flexible enough for the cooperative knowledge generation, will be overcome. The storage of knowledge and the supply of the members of the community are done with the help of knowledge networks. A knowledge network is a technical tool that can be used by the community to store their knowledge electronically. The persons of the community can combine their knowledge with other knowledge components of the knowledge network. Furthermore, members of the community have access to knowledge, which was stored by other persons of the community. An example for such a knowledge network is a Wiki. The requirements for a software tool that can be used in the outlined problem situation will be described in chapter 2. We show that the Wiki concept is an adequate approach to meet the requirements for a cooperative generation of knowledge (chapter 3). Thereafter, a concept for the integration of communities into process-oriented knowledge structures will be developed. For this purpose, an interface is designed that realises process and context specific views on the knowledge of the community (chapter 4). With the help of this interface synergies of the connection of communities and the process-oriented knowledge structures will be developed. 2 Connection of Process Structures and CommunitiesTo accomplish knowledge-intensive work processes, knowledge supply as well as (cooperative) knowledge generation is needed. In order to assure this, technologies of the knowledge management must be connected with tools for the support of communities in an appropriate way [Fuchs-Kittowski, 03b]. With the integration, the continuous development of the provided knowledge in a cooperative process must be reached. Page 411
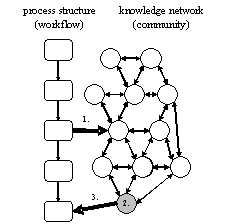
Figure 1: Connection of communities with work processes Therefore, a tool meeting the following additional requirements must be created:
The above-mentioned integration requirements are met by a concept for an interface that will be introduced in chapter 3. Page 412 3 Cooperative Knowledge Generation with the Wiki ApproachThe Wiki approach seems to be an adequate community solution to meet the requirements made for the IT support of the cooperative knowledge generation. Ward Cunningham developed the software "WikiWikiWeb" in 1995. The word "wiki wiki" derives from the Hawaiian language and means "fast" [Leuf, 01]. The word "Wiki" is used to name special documents (Wikis), to name the common concept of these documents (Wiki) or to name the used software (Wiki-Server, Wiki-Engine) [Cyganiak, 02].
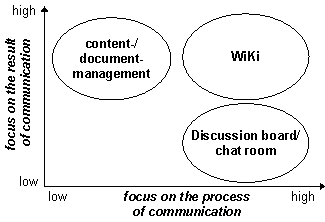
Figure 2: Communication-oriented classification A "Wiki" is an open authoring tool to create and maintain web pages within a community. In a "Wiki" information can be collected and links to further Wiki pages can be stored. Wiki software offers a fast and simple possibility to create and edit web pages online. The pages of the Wiki can be commented, modified, supplemented and even deleted from all users. New pages can be created easily and they can be linked to already existing pages. A Wiki-Web is mainly characterised by a simple interaction and navigation on the web pages. In this manner the boundaries between the (active) author and the (passive) user of contents are repealed. In doing so, a big chaotic formation of linked Wiki pages is built fast (knowledge network). All users or a limited group of users have central access to the Wiki-Web. That's why the Wiki-Web is suitable for the execution of projects, the development of documentations or the joint production of concepts. Furthermore, it can be used as a discussion forum. In the field of the knowledge management the Wiki-Web offers a special potential for the knowledge development. The provided knowledge can be changed and extended immediately without any big efforts. Thus, an integrated, interdisciplinary and cooperative knowledge base is the result. Page 413 The popularity of this approach is based on the following factors [Huhmann, 02]:
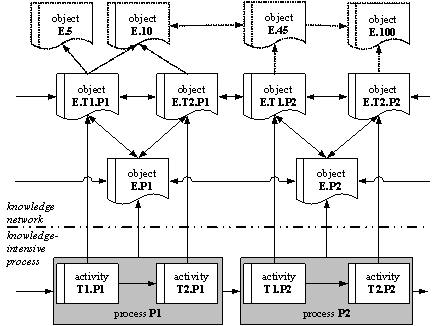
A Wiki can be used for different scenarios, e.g. as a content management system, as a discussion forum or as other forms of group ware. But the special characteristics of a Wiki have to be taken into account. New gained knowledge can be collected easily with the help of a Wiki and it can be integrated into the already existing knowledge base through the user himself. The specific advantage of the Wiki approach compared to other forms of the cooperative knowledge exchange and generation is that the process of communication as well as the result of the communication is focused. Content and document management systems have their focus rather on the exchange of the results of the cooperation. The result of communication processes for that document are difficult to handle, e.g. through the annotation on or in documents. Discussion forums rather focus on the process of the cooperation between the participants. Opinions can be changed and a common understanding will be created. But the result of the discussion mostly stays implicitly in the discussion contributions and has to be extracted and compressed later on. Wikis in contrast allow a discussion as well as the work on a common result at the same time. The above mentioned requirements on a tool to support the cooperative knowledge generation are largely fulfilled through the mentioned characteristics of a Wiki. In a Wiki the separation of author and reader is repealed. That's why the cooperative generation of contents is realised especially effectively. In the beginning, the big importance of the conscious and active benefit of the knowledge of other people was already explained. Furthermore the development of a common coherence through the establishment of communities of practice was postulated. These requirements can be fulfilled through a Wiki as well, because it supports the direct cooperation with other people very well. 4 Integration of Knowledge Networks into Process-Oriented StructuresThe concept of the integration of knowledge networks into process-oriented knowledge structures will be developed below. For this purpose an interface will be designed, which makes it possible to realise process and context specific views on the knowledge network. The developed integration concept is based on the idea that the knowledge network should not be developed detached from the process structure. Instead of that the process structure should be included as a design criteria. Page 414 The assumption, that the user of the knowledge network executes one of the known processes while a knowledge gap occurs, is a big clue for the design of the network. The situation of the user inside the just now executed process creates a context, in which the provided information will be interpreted. This context again can be used to make a process-oriented view possible on the knowledge network. This view can be used determining the context-specific relevance for each element of the network. A result of the developed integration concept is the description of the cooperation between the process model, the knowledge network and the corresponding interface. 4.1 Interface Modelling between the Process-oriented Structure and the Knowledge NetworkFacilitating a process-specific perspective of the knowledge network, an object associated with the corresponding process (step) must be anchored in the knowledge network. This object creates a one-to-one connection between a defined process-step on one side and network components on the other side. Figure 3 explains the structure of this interface model.
Figure 3: Interface modelling between process model and knowledge network In the lower part of the picture the processes P1 and P2 are illustrated as a section from a knowledge-intensive process. Both processes are each subdivided into two sub-steps (activities) T1 and T2. The arrows connecting the processes with their sub-steps show the sequence of their execution. The picture shows an example with two hierarchy levels. In principle, any number of levels is possible. Page 415 The arrows connecting the processes (sub-steps) with the components of the knowledge network represent the actual interface. Every part in knowledge-intensive processes can be matched with a one-to-one network component. With the help of these connections the process structure in the network can be automatically reproduced. Besides the referring links for illustrating the process structure, the network components contain predominantly links to those knowledge components on the net relevant for the respective processes. The development of such knowledge components and the creation of corresponding links are part of the change operations by the user. 4.2 Information Retrieval in an Integrated Knowledge NetworkThe interface linking knowledge-intensive process and the knowledge network permits the user to adjust the information retrieval to his potential information demand and accordingly evaluate the network components. Thus, we assume that two documents referring to each other have a contextual correlation [Croft, 89]. Furthermore, we assume a gradual reduction of relevance of a document for a specific process-step if the number of references between this process-step and the document increases. This is a model assumption describing the ideal-type network conditions that might not apply under real-life circumstances. Promoting a better understanding of this case, we introduce the term referential distance. The number of available documents will be described by D, the number of process-steps by P. If the relevance of a document d to a process-step p be rpd for p = 1...P and d = 1...D, the referential distance tpd represents the distance of the document to the origin of the reference-chain, the process p. The referential distance corresponds to the shortest distance between the point of origin and the correlating document measured with the number of the minimally necessary references. Thus, the potential relevance of a document compared to the origin of referencing can be described. With an increasing referential distance a decreasing of relevance can be expected. In case of a transformation of the entire knowledge network according to a process-specific perspective, the referential distance tpd compared to the present process-step respectively the interface component must be determined for every document d. Subsequently, all the documents with the same reference distance tpd can be pooled in so-called distance classes k. Regarding an extensive knowledge network with thousands of sites, it is easy to see that the referential distance can only roughly structure the relevance of documents. Since documents in the same distance class may differ considerably, a more precise distinction becomes inevitable. We assume that the relevance of a document in a distance class increases with the number of references from the same or a superior distance class. This is based on the assumption that the reference to a document can be interpreted as a vote for this document. This assumption is partly founded on the PageRankTM-Technology by L. Page and S. Brin, core piece of the extraordinarily successful search engine Google [Brin, 98]. A rating of a document in this sense is conducted solely on the basis of a vote of other documents with at least equal or higher relevance (based on the referential distance). This term will be defined as distance class-depending frequency of reference hkd within a distance class k. Page 416 These specific distance classes k as well as the corresponding frequencies of reference hkd serve as an instrument to bring the documents in a process-specific sequence. For determining the relevance rpd, the following function is applied:
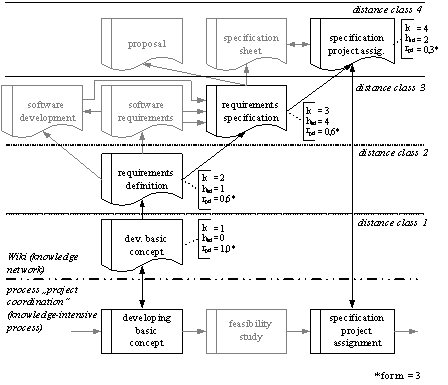
Formula 1: Relevance The value of the relevance initially decreases with the increasing distance class k. It can in turn be improved by references hkd to the document. K is therefore reduced by the quotient. The parameter m says which number of references would help to increase the relevance of a document in order to exceed its original distance class. The relevance of a document d = 1 out of the distance class k with hk1 = m would correspond to the relevance of a document d = 2 out of the distance class k-1 and h(k-1)1 = 1. In case of hk1 > m, the relevance of the document d = 1 has a value corresponding with the relevance of a document d = 2 with h(k-1)2 < m. The relevance of the given document can have a value ranging from 0 to 1, with rpd = 1 being the highest possible relevance. If the number of references would be so high as to exceed rpd = 1, rpd = 1 is assumed. The interface document always holds the relevance rpd = 1. In the following lines, the query algorithm will be exemplified. We assume a user in the middle of the process "developing a basic concept" who wants to search the Wiki looking for the term "requirements specifications" as part of the process. Figure 4 lists all the processes and Wiki-sites relevant for this process. Figure 4 also shows where (in which distance class) the individual sites are located from the point of view of the process "developing a basic concept". Moreover, the frequency of reference hkd as well as the process-specific relevance rpd of every site is revealed, based on the parameter m = 3. All the processes shown in figure 4 (black and grey) are searched for this term. In case of the document "developing a basic concept", the calculation of the relevance amounts to rpd = 1 based on the distance class k = 1. The frequency of reference hkd is zero since this site is referred to by no other Wiki-site and the reference from the process is only imaginarily made due to the above-described matching process. The document "requirements definition" is located in the distance class k = 2 and it has only one incoming link which results in a relevance of rpd = 0.6. The document "requirements specifications", which is located in the distance class k = 3, also has a process-specific relevance of rpd = 0.6. This value which seems to be atypical for this distance class derives from hkd = 4 references. In this case hkd > m which means the document "drops out" of its distance class. It receives the same relevance as the superior document "requirements definition" (seen from the process view). The document "specification project assignment" is characterised through k = 4 and hkd = 2 which results in a relevance of rpd = 0.3. This result will be sorted according to its relevance and it will be presented as figure 5 shows. Page 417
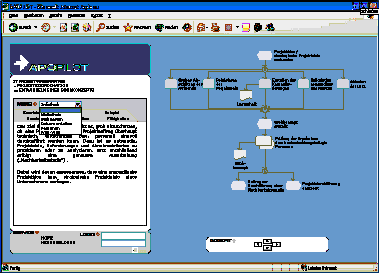
Figure 4: Diagrammatic illustration of a Wiki-section for the process "developing a basic concept" (explicit query) 5 Realisation of the PrototypeIn this chapter, we will introduce a tool meeting the above described specifications. This implementation consists of three components. First, the APO-Pilot is used as a process-oriented, global knowledge base. Second, the PmWiki will serve as the Community-Support-System supporting the process of cooperative knowledge generation. In addition to that, an interface according to the above-mentioned concept was implemented between the APO-Pilot and PmWiki. First, the APO-Pilot is shortly introduced. The implemented interface will be presented in greater detail subsequently. Page 418 5.1 The APO-Pilot: A Process-oriented Knowledge BaseWorking in knowledge-intensive work processes requires knowledge tied to the activities in the work process. With the APO-Pilot, a tool accompanying the work process was implemented that consistently follows the aspect of process-orientation. The APO-Pilot supports the process of generating knowledge in the work process and facilitates the backflow of new knowledge acquired by applying available resources, reflecting the work process and making practical experiences. The APO-Pilot facilitates a process-oriented navigation through the modelled work processes of a company. Working as an assistant without an active control, it visualises the run of the process as event-driven process chain and supports the structuring of the work process. Besides the supply of knowledge to supply the run of the process, every process-step and every activity is provided with different knowledge carriers helping the employee to cope with his tasks. These sources of knowledge, commonly distributed in different IT systems and independent from work processes are now integrated and structured in a uniform, process-oriented view. Every process-step and every operation will be provided with documents or other adequate learning material (e.g. from the intranet; domain "library"). Appropriate persons as competence carriers (experts etc.) are suggested with available means of communication (mail, telephone, video etc.) in the domain "people". In the "discussion" domain, discussion boards are supplied for exchanging experiences, perspectives and opinions as well as trouble shooting. In addition to that, an access to a Wiki will also be supplied for a process-spanning support of a cooperative knowledge generation.
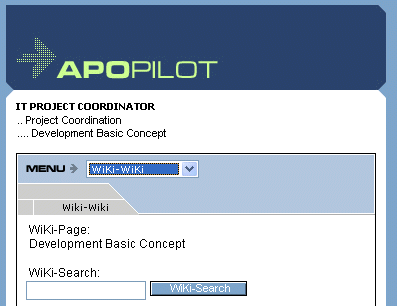
Figure 5: APO-Pilot Page 419 5.2 Cooperative Knowledge Generation: The PmWikiTo realise the Wiki for the APO-Pilot the PmWiki, which had been developed by Patrick R. Michaud [Michaud, 04], was used. The PmWiki is a small Wiki which is written in PHP. Adaptations regarding the content and the layout were necessary. On the one hand, the PmWiki was used because of its usability based on the GNU Public Licence. On the other hand, it is easily adaptable because of its implementation in PHP. Furthermore, the PmWiki has some characteristics which are unusual for Wikis, but necessary in connection with the use of the APO-Pilot. One of the characteristics is the possibility to organise documents in groups and to provide them with access authorization. Another important feature of the PmWiki is its expected continuous further development whereby a stable basis for the future development of the here introduced prototype is given. 5.3 Functionality of the InterfaceThe APO-Pilot, as an example for a knowledge base structured by processes, supplies every process-step or activity with an access to the Wiki. Starting from the current process, in this case "developing a basic concept", the corresponding Wiki-site can be addressed immediately or the entire Wiki is searched for a specific term (e.g. "requirements specification", see figure 6).
Figure 6: Wiki access page The direct call of the Wiki leads to the invocation of the correlating process-specific interface-document in a separate browser window. This Wiki-site can be edited, new sites can be created or the Wiki can be "navigated" through (see figure 7). Page 420
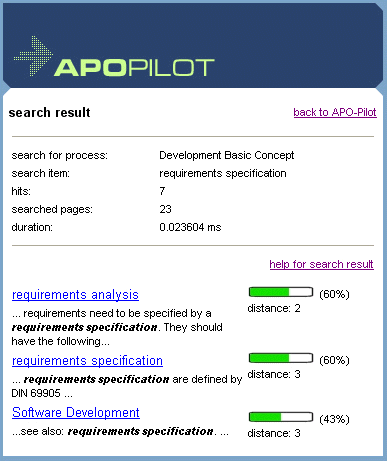
Figure 7: Interface page Looking for a search item in the Wiki, all the sites of the Wiki are searched. With the help of distance classes and distance class-depending frequency of reference of the chosen process-step, the hits will be screened, evaluated and presented according to their process-specific relevance (see figure 8).
Figure 8: Process-based searching result Beside the relevance, graphically expressed by a green bar as well as in percentage, the result also contains features of the correlating distance class ("distance"). Page 421 Furthermore, the name of the site and the context of the search item are presented. Clicking on the name of the site, the Wiki is opened in the corresponding place. The head of the site shows general information of the result of the query, particularly the process the query was conducted for. This piece of information is important since a query with the same search item for another process would have lead to a completely different result.
Figure 9: Return to the process model The return to the APO-Pilot is possible from every Wiki-site. If the current site is an interface-site, the corresponding process-step will be opened in the APO-Pilot. In case of finding no matching site, all those process-steps with the shortest referential distance compared to the chosen Wiki-site are determined. Simultaneously, the user is provided with a facility to return to the APO-Pilot. 5.4 Technological Design of the InterfaceThe connection of the APO-Pilot and the PmWiki is realised through a communication via HTTP. Both programmes make their enquiries to an interface file, which is written in PHP. Furthermore, a mapping file is necessary which contains the process identifiers and the associated HTML page names of the APO-Pilot. The mapping file is necessary for the interface file to determine the corresponding APO or Wiki page on the basis of the process name or to execute a process-specific search. The interface documents will be created automatically by calling a page with the corresponding process name in the Wiki. If this page doesn't exist, it will be created automatically and it can be completed with content by the user. To increase the flexibility of the above mentioned components they can be stored spatially spread. An appropriate customisation of the interface is possible with the help of parameters. Page 422 6 SummaryKnowledge-intensive processes are characterised predominantly by problems that cannot be anticipated, containing beside a process-related supply of available knowledge sources also processes of cooperative problem solving. Due to a high complexity of problems, cooperative problem solving requires a process-spanning exchange of knowledge. It became clear that knowledge communities can highly contribute to increase the intrinsic motivation for sharing knowledge by creating a platform for Communities of Practice. The Wiki approach was introduced as a technological means to realise a knowledge network like this. With the help of the Wiki the classical roles "author" and "recipient" are removed. Creating synergies in combining knowledge networks and process-oriented knowledge structures was described by the integration concept. The core piece of this concept is an interface that facilitates process-specific perspectives of the knowledge of the community (knowledge network) on the basis of the referential distance and the distance class-depending frequency of reference of a document. In conclusion, a prototype implementation could be presented and executed on the basis of an integration concept (Wiki into APO-Pilot). With the prototype-implementation of a Wiki in the APO-Pilot, we managed to develop a tool for a cooperative knowledge generation while considering the afore-mentioned requirements. The particularly low usage barrier due to the easy and intuitive usability of the Wiki as well as the improvement of the information retrieval process in the knowledge network by using process structures serve as examples for that. In the implementation and test phase, the following features of the tool turned out to be of advantage:
In general terms, the prototype can be considered as a successful implementation of the integration concept. In an ideal case, this result should be approved in a usability test in a next step, as strong and weak points will only occur in daily business. These will be realised by the learner in the execution of real-life cooperative processes. In the following, some aspects will be given that could be taken into consideration for the further development of the presented concept. 6.1 Community-dependent WikisDifferent Wikis for different user groups could be an alternative. Especially if there are very large communities, this procedure could be interesting to obtain the incentive for knowledge sharing. In too large communities the individual maybe doesn't feel perceived or there are problems in understanding because of too many departments that are represented in the Wiki. The perception as an expert is one of central requirements for an efficient Community of Practice [Lave, 91; Maslow, 70]. Page 423 6.2 Typified LinksThe associative links that are used in Wikis show semantic resemblance between two documents. But mostly, it is not obvious, if the referenced document is a definition, a discussion about the topic or an open article. With the help of typified links it would be possible to inform the user about the expected document type before he activates the link. Such possibilities are already provided through the HTML 4.0 Standard [W3C, 98]. 6.3 Topic Maps to Structure WikisTopic Maps could be used to classify documents in large Wikis. In this manner, a meta level could be created which can be compared with a community dependent glossary. The users of the Wiki would have to maintain the glossary and so they would systematise the community dependent technical terms. The Topic Map itself could contain links to the appropriate Wiki pages [Pepper, 00]. References[Brin, 98] S. Brin, L. Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, Computer Science Department, Stanford University, 1998, http://www-db.stanford.edu/~backrub/google.html [Brown, 89] J. S. Brown, A. Collins, P. Duguid, Situated Cognition and the Culture of Learning. In: Education Researcher 18, 1, 1989, 32-42 [Croft, 89] W. Croft, H. Turtle, A Retrieval Model Incorporating Hypertext Links, In: Hypertext'89, Proceedings, November 5-8 1989, Pittsburgh, USA, ACM, 213-224 [Cyganiak, 02] R. Cyganiak, Wiki und WCMS: Ein Vergleich, Freie Universität Berlin, In: http://page.inf.fu-berlin.de/~cyganiak/cm/wiki_und_wcms.pdf, viewed on October 12th 2004 [Fuchs-Kittowski, 03a] F. Fuchs-Kittowski, K. Manski, D. Faust, M. Prehn, I. Schwenzien, Arbeitsprozessorientiertes E-Learning mit Methoden und Werkzeugen des prozessorientierten Wissensmanagement, In A. Bode et al.: DeLFI 2003: Tagungsband der 1. e-Learning Fachtagung Informatik, 16.-18.9.2003, Lecture Notes in Informatics (LNI) - Proceedings, Volume P-37, 392-401 [Fuchs-Kittowski, 03b] F. Fuchs-Kittowski, Wissensmanagement und E-Collaboration, In: KnowTech 2003, 5. Konferenz zu Knowledge Engineering & Management, Munich [Huhmann, 02] J. Huhmann, Schnell, schnell, In: iX: Magazin für professionelle Informationstechnik 10, 2002, 84-87 [Lave, 91] J. Lave, E. Wenger, Situated Learning: Legitimate Peripheral Participation, Cambrigde: University Press, 1991 [Leuf, 01] B. Leuf, W. Cunningham, The Wiki Way: Quick Collaboration on the Web, Longman: Addison-Wesley 2001 [Maslow, 70] A. H. Maslow, Motivation and Personality, New York: Harper & Row, 1970 Page 424 [Michaud, 04] P. Michaud, PmWiki, http://www.pmichaud.com/wiki/Experimental, viewed on October 12th 2004 [Pepper, 00] S. Pepper, The TAO of Topic Maps: Finding the Way in the Age of Infoglut, XML Europe 2000, http://www.gca.org/papers/xmleurope2000/pdf/s11-01.pdf [W3C, 98] HTML 4.0 Specification, W3C Recommendation, 1998, http://www.w3.org/TR/1998/REC-html40-19980424/ Page 425 |
|||||||||||||||||