| Submission Procedure |
Increasing Robustness of LSB Audio Steganography by Reduced Distortion LSB CodingNedeljko Cvejic Tapio Seppänen Abstract: In this paper, we present a novel high bit rate LSB audio watermarking method that reduces embedding distortion of the host audio. Using the proposed twostep algorithm, watermark bits are embedded into higher LSB layers, resulting in increased robustness against noise addition. In addition, listening tests showed that perceptual quality of watermarked audio is higher in the case of the proposed method than in the standard LSB method. Key Words: audio steganography, LSB coding, data hiding 1 IntroductionMultimedia data hiding techniques have developed a strong basis for steganography area with a growing number of applications like digital rights management, covert communications, hiding executables for access control, annotation etc. In all application scenarios given above, multimedia steganography techniques have to satisfy two basic requirements. The first requirement is perceptual transparency, i.e. cover object (object not containing any additional data) and stego object (object containing secret message) must be perceptually indiscernible [Anderson and Petitcolas 2001]. The second constraint is high data rate of the embedded data. All the stegoapplications, besides requiring a high bit rate of the embedded data, have need of algorithms that detect and decode hidden bits without access to the original multimedia sequence (blind detection algorithm). While the robustness against intentional attack is not required, a certain level of robustness of hidden data against common signal processing as noise addition or MPEG compression may be necessary. LSB coding is one of the earliest techniques studied in the information hiding and watermarking area of digital audio [Yeh and Kuo 1999], [Cedric et al. 2000] (as well as other media types [Lee and Chen 2000], [Fridrich et al. 2002]). The main advantage of the LSB coding method is a very high watermark channel bit rate and a low computational complexity of the algorithm, while the main disadvantage is considerably low robustness against signal processing modifications. Page 56 2 Standard LSB methodData hiding in the least significant bits (LSBs) of audio samples in the time domain is one of the simplest algorithms with very high data rate of additional information. The LSB watermark encoder usually selects a subset of all available host audio samples chosen by a secret key. The substitution operation on the LSBs is performed on this subset, where the bits to be hidden substitute the original bit values. Extraction process simply retrieves the watermark by reading the value of these bits from the audio stego object. Therefore, the decoder needs all the samples of the stego audio that were used during the embedding process. The random selection of the samples used for embedding introduces low power additive white Gaussian noise (AWGN). It is well known from the psychoacoustics literature [Zwicker 1982] that the human auditory system (HAS) is highly sensitive to AWGN. That fact limits the number of LSBs that can be imperceptibly modified during watermark embedding. The main advantage of the LSB coding method is a very high watermark channel bit rate; use of only one LSB of the host audio sample gives capacity of 44.1 kbps (sampling rate 44 kHz, all samples used for data hiding) and a low computational complexity. The obvious disadvantage is considerably low robustness, due to fact that simple random changes of the LSBs destroy the coded watermark [Mobasseri 1998]. As the number of used LSBs during LSB coding increases or, equivalently, depth of the modified LSB layer becomes larger, probability of making the embedded message statistically detectable increases and perceptual transparency of stego objects is decreased. Therefore, there is a limit for the depth of the used LSB layer in each sample of host audio that can be used for data hiding. Subjective listening test showed that, in average, the maximum LSB depth that can be used for LSB based watermarking without causing noticeable perceptual distortion is the fourth LSB layer when 16 bits per sample audio sequences are used. The tests were performed with a large collection of audio samples and individuals with different background and musical experience. None of the tested audio sequences had perceptual artifacts when the fourth LSB has been used for data hiding, although in certain music styles, the limit is even higher than the fourth LSB layer. Robustness of the watermark, embedded using the LSB coding method, increases with increase of the LSB depth used for data hiding. Therefore, improvement of watermark robustness obtained by increase of depth of the used LSB layer is limited by perceptual transparency bound, which is the fourth LSB layer for the standard LSB coding algorithm. Page 57 3 Proposed LSB methodWe developed a novel method that is able to shift the limit for transparent data hiding in audio from the fourth LSB layer to the sixth LSB layer, using a twostep approach. In the first step, a watermark bit is embedded into the ith LSB layer of the host audio using a novel LSB coding method. In the second step, the impulse noise caused by watermark embedding is shaped in order to change its white noise properties. The standard LSB coding method simply replaces the original host audio bit in the ith layer (i=1,...,16) with the bit from the watermark bit stream. In the case when the original and watermark bit are different and ith LSB layer is used for embedding the error caused by watermarking is 2 i-1 quantization steps (QS)(amplitude range is [32768, 32767]). The embedding error is positive if the original bit was 0 and watermark bit is 1 and vice versa. The key idea of the proposed LSB algorithm is watermark bit embedding that causes minimal embedding distortion of the host audio. It is clear that, if only one of 16 bits in a sample is fixed and equal to the watermark bit, the other bits can be flipped in order to minimize the embedding error. For example, if the original sample value was 0...010002 =810 , and the watermark bit is zero is to be embedded into 4th LSB layer, instead of value 0...000002 =010 , that would the standard algorithm produce, the proposed algorithm produces sample that has value 0...001112 =710 , which is far more closer to the original one. However, the extraction algorithm remains the same, it simply retrieves the watermark bit by reading the bit value from the predefined LSB layer in the watermarked audio sample. In the embedding algorithm, the (i+1)th LSB layer (bit a i ) is first modified by insertion of the present message bit. Then, the algorithm given below is run. In case that the bit a i need not be modified at all due to being already at a correct value, no action is taken with that signal sample. Underlined bits (ai ) represent bits of watermarked audio. Algorithm: Improved LSB embedding if host sample a>0 else if bit 1 is to be embedded Page 58 if
a i-1 =1 then a i-1ai-2
...a 0 =00...0 if host sample a<0 else
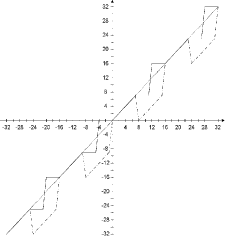
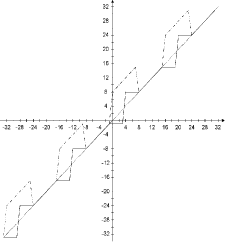
if bit 1 is to be embedded The embedding characteristic of the proposed LSB coding algorithm is given in the Figure 1, for the case when watermark bit is equal to zero, and in Figure 2, for the case when the watermark bit equals one. Figures depict an example of the embedding characteristics where the 4th LSB layer is used for watermarking; the values obtained by the proposed LSB method are represented as the dotted line. It is clear that the proposed method introduces smaller error during watermark embedding. If the 4th LSB layer is used, the absolute error value ranges from 1 to 4 QS, while the standard method (dashdot line) in the same conditions causes constant absolute error of 8 QS. The average power of introduced noise is therefore 9.31 dB smaller if the proposed LSB coding method is used. In addition to decreasing objective quality measure, expressed as signal to noise ratio (SNR) value, proposed method introduces, in the second step of embedding, noise shaping in order to increase perceptual transparency of the method. A similar concept, called error diffusion method is commonly used in conversion of true color images to palettebased color images [Mintzer et al. 1998]. In our algorithm, embedding error is spread to the four consecutive samples, as samples that are predecessors of the current sample cannot be altered because information bits have already been embedded into their LSBs. Page 59
Let e(n) denote the embedding error of the sample a(n). For the case of embedding into the 4th LSB layer, the next four consecutive samples of the host audio are modified according to these expressions: a(n+1)=a(n+1)+ where Therefore, we expect that, using the proposed twostep algorithm, we can increase the depth of watermark embedding further than the 4th LSB layer and accordingly increase algorithm's robustness towards noise addition. 4 Experimental resultsProposed LSB watermarking algorithm was tested on 10 audio sequences from different music styles (pop, rock, techno, jazz). The audio excerpts were selected so that they represent a broad range of music genres, i.e. audio clips with different dynamic and spectral characteristics. Page 60 All music pieces have been watermarked using the proposed and standard LSB watermarking algorithm. Clips were 44.1 kHz sampled mono audio files, represented by 16 bits per sample. Duration of the samples ranged from 10 to 15 seconds. As defined in [Bassia et al. 2001], signal to
noise ratio for the embedded watermark is computed as: SNR = 10 ·
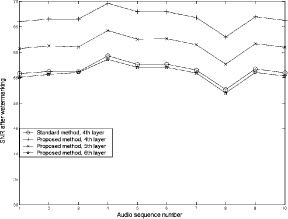
log10 Figure 3: SNR values of 10 test audio sequences for standard and proposed LSB watermarking method was performed by listening tests involving ten persons. Three of them had basic or medium level music education or are active musicians. In the first part of the test, participants listened to the original and the watermarked audio sequences and were asked to report dissimilarities between the two signals, using a 5point impairment scale: (5: imperceptible, 4: perceptible but not annoying, 3: slightly annoying, 2:annoying 1: very annoying). Page 61 Table 1 presents results of the first test, with the average mean opinion score (MOS) for three of the 10 tested audio excerpts. In the second part, test participants were repeatedly presented with unwatermarked and watermarked audio clips in random order and were asked to determine which one is the watermarked one (blind audio watermarking test). Experimental results are presented also in Figure 4. Values near to 50% show that the two audio clips (original audio sequence and watermarked audio signal) cannot be discriminated by people that participated in the listening tests. Results of subjective tests showed that perceptual quality of watermarked Values near to 50% show that the two audio clips (original audio sequence and watermarked audio signal) cannot be discriminated by people that participated in the listening tests. Results of subjective tests showed that perceptual quality of watermarked audio, if embedding is done using the novel algorithm, is higher in comparison to standard LSB embedding method. Discrimination values and mean opinion scores in the case of proposed algorithm embedding in the 6th LSB layer are practically the same as in the case of the standard algorithm embedding in the 4th LSB layer. This confirms that described algorithm succeeds in increasing the depth of the embedding layer from 4th to 6th LSB layer without affecting the perceptual transparency of the watermarked audio signal. Therefore, a significant improvement in robustness against signal processing manipulation can be obtained, as the hidden bits can be embedded two LSB layers deeper than in the standard LSB method. In order to compare the robustness of the proposed algorithm and the standard one, additive white Gaussian noise was added to the samples of watermarked audio and bit error rate (BER) measured.
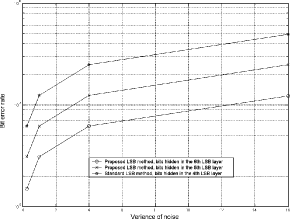
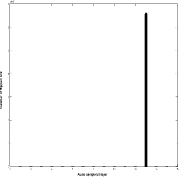
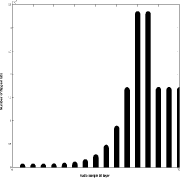
Figure 4: Mean opinion scores and discrimination values The values given in Figure 5 are for 44.1 kbps embedding rate and calculated as number of flipped hidden bits over the total number of received bits. The improvement in robustness against additive noise is obvious, as the proposed algorithm obtains significantly lower bit error rates than the standard algorithm if the same noise variance is added to the watermarked audio. Page 62 Figure 5: Robustness of the algorithms in presence of additive white Gaussian noise As described above, the proposed algorithm flips bits in more than one bit layers of the watermarked audio during the embedding procedure. This property may increase the resistance against steganalysis that identifies the used LSB layer by analyzing the noise properties of each bit layer. Figures 6 and 7 show histogram of the number of modified bit layers in a 1.5 sec audio sample (66150 bits in total) for the standard and proposed LSB algorithm, respectively. It is clear that number of flipped bits per bit layers is distributed over all bit layers in the proposed algorithm, while the standard algorithm flips bits only in one bit layer. In the case of standard LSB algorithm, LSB steganography techniques [Dumitrescu et al. 2002] can easily detect the bit layer where the data hiding was performed. It is a much more challenging task in the case of the proposed algorithm, because there is a significant number of bits flipped in seven bit layers and the adversary cannot identify exactly which bit layer is used for the data hiding. 5 ConclusionWe presented a reduced distortion bitmodification algorithm for LSB audio steganography. The key idea of the algorithm is watermark bit embedding that causes minimal embedding distortion of the host audio. Page 63
Listening tests showed that described algorithm succeeds in increasing the depth of the embedding layer from 4th to 6th LSB layer without affecting the perceptual transparency of the watermarked audio signal. The improvement in robustness in presence of additive noise is obvious, as the proposed algorithm obtains significantly lower bit error rates than the standard algorithm. The steganalysis of the proposed algorithm is more challenging as well, because there is a significant number of bits flipped in a number in bit layers and the adversary cannot identify exactly which bit layer is used for the data hiding. References[Anderson and Petitcolas 2001] Anderson, R., Petitcolas, F.: On the limits of the steganography, IEEE Journal Selected Areas in Communications, 16, 4,474-481. [Bassia et al. 2001] Bassia, P., Pitas, I., Nikolaidis, N.: Robust audio watermarking in the time domain, IEEE Transactions on Multimedia, 3, 2, 232-241. [Cedric et al. 2000] Cedric, T., Adi, R.,Mcloughlin, I.: Data concealment in audio using a nonlinear frequency distribution of PRBS coded data and frequencydomain LSB insertion, Proc. IEEE Region 10 International Conference on Electrical and Electronic Technology, Kuala Lumpur, Malaysia, 275278. [Dumitrescu et al. 2002] Dumitrescu, S., Wu, W., Memon, N.: On steganalysis of random LSB embedding in continuoustone images, Proc. International Conference on Image Processing, Rochester, NY, 641-644. Page 64 [Fridrich et al. 2002] Fridrich, J., Goljan, M., Du, R.: (2002) Lossless Data Embedding - New Paradigm in Digital Watermarking, Applied Signal Processing, 2002, 2, 185-196. [Lee and Chen 2000] Lee, Y., Chen, L.: High capacity image steganographic model, IEE Proceedings on Vision, Image and Signal Processing, 147, 3, 288-294. [Mintzer et al. 1998] Mintzer, F., Goertzil, G., Thompson, G.: Display of images with calibrated colour on a system featuring monitors with limited colour palettes, Proc. SID International Symposium, 377-380. [Mobasseri 1998] Mobasseri, B.: Direct sequence watermarking of digital video using mframes, Proc. International Conference on Image Processing, Chicago, IL, 399-403. [Yeh and Kuo 1999] Yeh, C., Kuo, C.: Digital Watermarking through Quasi mArrays, Proc. IEEE Workshop on Signal Processing Systems, Taipei, Taiwan, 456461. [Zwicker 1982] Zwicker, E.: Psychoacoustics, Springer Verlag, Berlin, Germany. Page 65 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 e(n)
e(n) a(n+3)=a(n+3)+
a(n+3)=a(n+3)+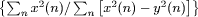 where x(n) represents a sample of input audio sequence and y(n) stands
for a sample of audio with modified LSBs. SNR values for the standard method
(embedding performed in the 4th LSB layer) and the proposed method
(embedding performed in the 4th ,5th and 6th LSB layer) are given in
where x(n) represents a sample of input audio sequence and y(n) stands
for a sample of audio with modified LSBs. SNR values for the standard method
(embedding performed in the 4th LSB layer) and the proposed method
(embedding performed in the 4th ,5th and 6th LSB layer) are given in