|
Balanced PRAM Simulations via Moving Threads and Hashing
Ville Leppänen (Department of Computer Science, University of Turku, Finland)
Abstract: We present a novel approach to parallel computing, where (virtual) PRAM processors are represented as light-weight threads, and each physical processor is capable of managing several threads. Instead of moving read and write requests, and replies between processor&memory pairs (and caches), we move the light-weight threads. Consequently, the processor load balancing problem reduces to the problem of producing evenly distributed memory references. In PRAM computations, this can be achieved by properly hashing the shared memory into the processor&memory pairs. We describe the idea of moving threads, and show that the moving threads framework provides a natural validation for Brent's theorem in work-optimal PRAM simulation situations on mesh of trees, coated mesh, and OCPC based distributed memory machines (DMMs). We prove that an EREW PRAM computation 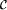 requiring work W and time T, can be implemented work-optimally on those p-processor DMMs with high probability, if W = requiring work W and time T, can be implemented work-optimally on those p-processor DMMs with high probability, if W = 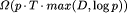 , where D is the diameter of the underlying routing machinery. The computation is work-optimal regardless how (virtual) PRAM processors terminate or initiate new PRAM processors during the computation. , where D is the diameter of the underlying routing machinery. The computation is work-optimal regardless how (virtual) PRAM processors terminate or initiate new PRAM processors during the computation. Our result is based on using only one randomly chosen hash function and on showing, how the threads (PRAM processors) can spawn new threads in required time on p-processor OCPC, 2-dimensional mesh of trees, 2-dimensional coated, and 3-dimensional coated mesh. A deterministic spawning algorithm is provided for all cases, although a randomized algorithm would be sufficient due to the randomized nature of time-processor optimal PRAM simulations.
Keywords: EREW, OCPC, balanced workload, coated mesh, mesh of trees, moving threads, randomized, shared memory, simulation, work-optimal
Categories: C.1.2, C.2, C.5, F.1, F.2, G.3
|