Grammars based on the shuffle operation
Gheorghe Paun
Institute of Mathematics of the Romanian Academy of Sciences
PO Box 1 - 764, Bucuresti, Romania
Grzegorz Rozenberg
University of Leiden, Department of Computer Science
Niels Bohrweg 1, 2333 CA Leiden, The Netherlands
Arto Salomaa
Academy of Finland and University of Turku
Department of Mathematics, 20500 Turku, Finland
Abstract: We consider generative mechanisms producing
languages by starting from a finite set of words and shuffling the
current words with words in given sets, depending on certain
conditions. Namely, regular and finite sets are given for controlling
the shuffling: strings are shuffled only to strings in associated
sets. Six classes of such grammars are considered, with the shuffling
being done on a left most position, on a prefix, arbitrarily,
globally, in parallel, or using a maximal selector. Most of the
corresponding six families of languages, obtained for finite,
respectively for regular selection, are found to be incomparable. The
relations of these families with Chomsky language families are briefly
investigated. Categories: F4.2 [Mathematical Logic and Formal
Languages]: Grammars and other Rewriting Systems: Grammar types, F4.3
[Mathematical Logic and Formal Languages]: Formal Languages: Operations
on languages Keywords: Shuffle operation, Chomsky grammars, L Systems
1. Introduction
In formal language theory, besides the basic two types of grammars,
the Chomsky grammars and the Lindenmayer systems, there are many
"exotic" classes of generative devices, based not on the process of
rewriting symbols (or strings) by strings, but using various
operations of adjoining strings. We quote here the string adjunct
grammars in [7], the semi-contextual grammars in [3], the
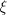 -grammars in [10], the pattern grammars in [2], and the
contextual grammars [8]. The starting point of the present paper is
this last class of grammars, via the paper [9], where a variant of
contextual grammars was introduced based on the shuffle operation.
Basically, one gives two finite sets of strings, -grammars in [10], the pattern grammars in [2], and the
contextual grammars [8]. The starting point of the present paper is
this last class of grammars, via the paper [9], where a variant of
contextual grammars was introduced based on the shuffle operation.
Basically, one gives two finite sets of strings,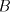 and and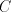 , over
some alphabet, and one considers the set of strings obtained by
starting from , over
some alphabet, and one considers the set of strings obtained by
starting from 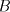 and iteratively shuffling strings from and iteratively shuffling strings from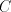 , without
any restriction. This corresponds to the simple contextual grammars in
[8]. , without
any restriction. This corresponds to the simple contextual grammars in
[8]. We consider here a sort of couterpart of the contextual grammars with choice,
where the adjoining is controlled by a selection mapping. In fact, we proceed
in a way similar to that used in conditional contextual grammars [12], [13],
[14] and in
modular contextual grammars [15]: we start with several pairs of the form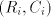 , ,
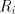 a language (we consider here only the case when is regular
or finite) and a language (we consider here only the case when is regular
or finite) and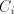 a finite set of strings, and allow the strings
in to be shuffled only to strings in. Depending on the place of the
string in in the current string generated by our grammar, we can distinguish
several types of grammars: prefix (the string in appears in the left-hand of
the processed string, as a prefix of it), leftmost (we look for the leftmost possible occurrence of
a string in), arbitrary (no condition on the place where the string in appears),
global (the whole current string is in), and parallel (the current string is
portioned into strings in). An interesting variant is to use a substring
as base for shuffling only when it is maximal. Twelve families of languages are obtained in this
way. Their study is the subject of this paper. a finite set of strings, and allow the strings
in to be shuffled only to strings in. Depending on the place of the
string in in the current string generated by our grammar, we can distinguish
several types of grammars: prefix (the string in appears in the left-hand of
the processed string, as a prefix of it), leftmost (we look for the leftmost possible occurrence of
a string in), arbitrary (no condition on the place where the string in appears),
global (the whole current string is in), and parallel (the current string is
portioned into strings in). An interesting variant is to use a substring
as base for shuffling only when it is maximal. Twelve families of languages are obtained in this
way. Their study is the subject of this paper. It is worth noting that the shuffle operation appears in various contexts in
algebra and in
formal language theory; we quote only [1], [4], [5], [6] (and [11], for applications). In
[1], [6] the operation is used in a generative-like way, for identifying families
of languages of the form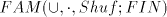 , the smallest family
of languages containing the finite languages and closed under union, concatenation
and shuffle. (From this point of view, the family investigated in [9] is a
particular case, , the smallest family
of languages containing the finite languages and closed under union, concatenation
and shuffle. (From this point of view, the family investigated in [9] is a
particular case,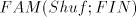 ). ). Page 67
The shuffle of the symbols of two words is also related to the concurrent
execution of two processes described by these words,
hence our models can be
interpreted in terms of concurrent processes, too. For instance, the prefix
mode of work corresponds to the concurrent execution of a process strictly at
the beginning of another process, the 'beginning' being defined modulo a
regular language; in the global case the elementary actions of the two processes can be
freely intercalated. As it is expected, the languages generated by shuffle grammars are mostly
incomparable with Chomsky
languages (due to the fact
that we do not use nonterminals). Somewhat
surprising is the fact that in the regular selection case the five modes of work described above, with only
one exception, cannot simulate each other (the corresponding families
of languages are incomparable).
2. Classes of shuffle grammars
As usual,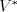 denotes the set of all words over the alphabet denotes the set of all words over the alphabet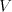 , the
empty word is denoted by , the
empty word is denoted by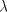 , the length of , the length of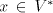 by by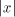 and the
set of non-empty words over and the
set of non-empty words over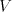 is identified by is identified by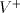 . The number of occurrences of
a symbol . The number of occurrences of
a symbol in a string in a string will be denoted by will be denoted by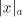 . For basic notions in
formal language theory (Chomsky grammars and L systems) we refer to [16], [17].
We only mention that . For basic notions in
formal language theory (Chomsky grammars and L systems) we refer to [16], [17].
We only mention that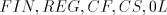 are the families of finite, regular,
context-free, context-sensitive, and of 0L languages, respectively. are the families of finite, regular,
context-free, context-sensitive, and of 0L languages, respectively. For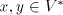 we define the shuffle (product) of we define the shuffle (product) of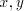 , denoted , denoted
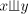 , as , as 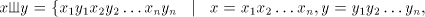 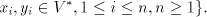
Various properties of this operation, such as commutativity and associativity,
will be implicitely used in the sequel. The operation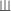 is extended in the
natural way to languages, is extended in the
natural way to languages, 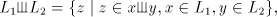
and iterated, 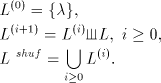
The grammars considered in [9] are triples of the form where where
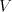 is an alphabet, is an alphabet,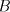 and and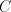 are finite languages over are finite languages over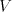 . The language generated
by . The language generated
by is defined as the smallest language is defined as the smallest language over over containing containing and having the
property that if and having the
property that if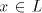 and and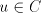 , then , then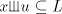 . (Therefore, this
language is equal to . (Therefore, this
language is equal to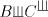 .) .) There is no restriction in [9] about the shuffling of elements of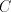 to current
strings. Such a control of the grammar work can be done in various ways of
introducing a context-dependency. We use here the following natural idea: to current
strings. Such a control of the grammar work can be done in various ways of
introducing a context-dependency. We use here the following natural idea: Definition 1.
A shuffle grammar is a construct 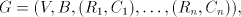
where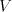 is an alphabet, is an alphabet,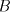 is a finite language over is a finite language over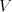 , ,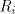 are
languages over are
languages over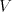 and and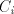 are finite languages over are finite languages over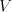 , ,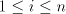 . . The parameter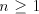 is called the degree of is called the degree of
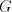 . If . If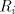 are languages in a
given family are languages in a
given family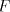 , ,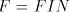 then we say that then we say that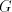 is with is with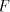 choice. Here we consider only
the casesand choice. Here we consider only
the casesand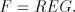 The idea is to allow the strings in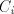 to be shuffled only to strings in the
corresponding set to be shuffled only to strings in the
corresponding set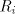 . The sets . The sets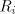 are called selectors. are called selectors. Page 68
Definition 2.
For a shuffle grammar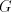 as above, a constant as above, a constant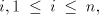 ,
and two strings ,
and two strings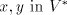 , we define the following derivation relations: , we define the following derivation relations: 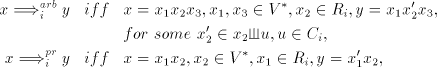
These derivation relations are called arbitrary, prefix, leftmost, and
global derivations, respectively. Moreover, we define the parallel derivation
as 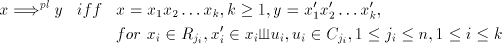 . .
We denote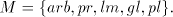 . . Definition 3. The language generated by a shuffle grammar in the mode in the mode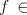 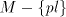 is defined as follows: is defined as follows: 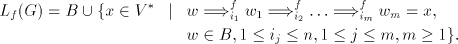
For the parallel mode of derivation we define 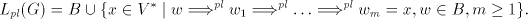
The corresponding families of languages generated by shuffle grammars
with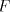 choice, choice,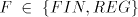 , are denoted by , are denoted by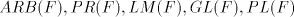 ,
respectively;
by ,
respectively;
by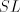 we denote the family of languages generated by grammars as in [9], without
choice. Subscripts we denote the family of languages generated by grammars as in [9], without
choice. Subscripts can be added to can be added to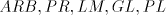 when only
languages generated by grammars of degree at most when only
languages generated by grammars of degree at most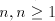 , are considered. , are considered.
3 The generative capacity of shuffle grammars
From definition we have the inclusions 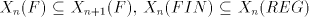 for all for all 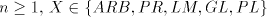 ,and ,and 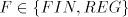 . . Every family 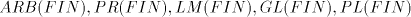 contains each
finite language. This is obvious, because for contains each
finite language. This is obvious, because for  we have we have  for all for all 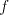 . In fact, we have . In fact, we have Theorem 1.
- (i)
- Every family
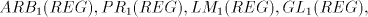 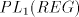 includes strictly the family SL. includes strictly the family SL.
- (ii)
- The family SL is incomparable with each
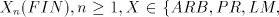 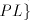 . .
- (iii)
-
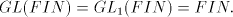 . .
Proof. (i) If 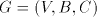 is a simple shuffle grammar, then is a simple shuffle grammar, then 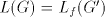 for each for each 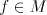 and and 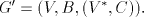
Page 69
(The only point which needs some discussion is the fact that a parallel
derivation 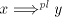 in in 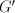 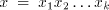 and and
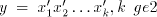 , can be simulated by a , can be simulated by a 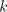 -step derivation
in -step derivation
in 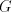 , because the strings shuffled into , because the strings shuffled into 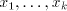 do not overlap
each other.) Consequently, do not overlap
each other.) Consequently, 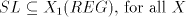 . . The inclusion is proper in view of the following necessary condition for a language
to be in 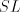 (Lemma 10 in [9]): if (Lemma 10 in [9]): if 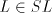 and and 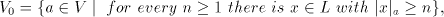
then each string in 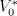 is a subword of a string in is a subword of a string in 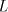 , condition
rejects languages such as , condition
rejects languages such as 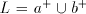 ; this language can be generated by
the shuffle grammar with finite choice ; this language can be generated by
the shuffle grammar with finite choice 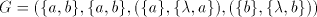
in all modes of derivation excepting the global one. For 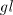 take take 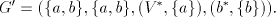
(ii) We have already seen that 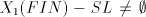 for for 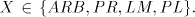 Consider now the simple shuffle grammar
Consider now the simple shuffle grammar 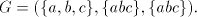
We have 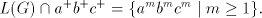
Assume that 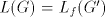 for some shuffle grammar for some shuffle grammar
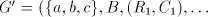 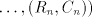 with finite with finite 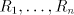 and and 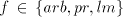 Take a string
Take a string 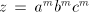 with arbitrarily large with arbitrarily large 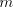 . A derivation . A derivation
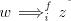 must be possible in must be possible in 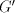 , with , with 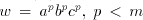 for some for some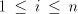 . We must have . We must have 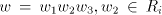 , and , and 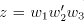 for
for
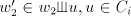 . If . If 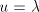 , this derivation step can be
omitted, hence we may assume that , this derivation step can be
omitted, hence we may assume that 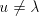 . . The sets 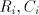 are finite. Denote are finite. Denote 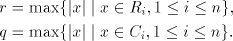
Therefore 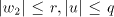 , that is , that is 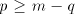 . For . For 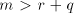 we have we have
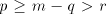 , hence either , hence either 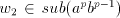 or or 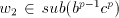 .
In both cases, the shuffling
with .
In both cases, the shuffling
with  modifies at most two of the three subwords modifies at most two of the three subwords 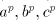 , hence a parasitic string is obtained. (In the prefix derivation case we
precisely know that only , hence a parasitic string is obtained. (In the prefix derivation case we
precisely know that only 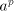 is modified.) is modified.) Consider now the parallel case. Take 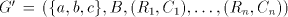 such that
such that 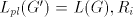 finite sets. For obtaining a string finite sets. For obtaining a string 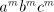 with large enough
with large enough 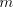 we need a derivation we need a derivation 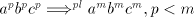 .
This implies we have sets .
This implies we have sets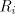 containing strings containing strings
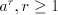 and with the
corresponding sets and with the
corresponding sets 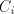 containing strings containing strings 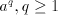 (similarly for (similarly for 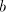 and and  ). ). Assume that we find in the sets 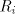 two strings two strings 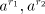 and in the associated
sets and in the associated
sets 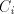 we find two strings we find two strings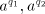 . Similarly, we have pairs . Similarly, we have pairs 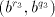 and
and 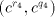 .
The string .
The string 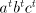 for for 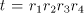 is in is in  and it can be rewritten
using the same pairs of strings containing the symbols and it can be rewritten
using the same pairs of strings containing the symbols
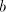 and and  and different pairs for and different pairs for  : : 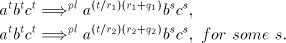
Consequently, we must have 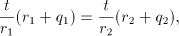
which implies 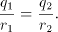
Page 70
For all such pairs 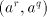 we obtain the same value for we obtain the same value for 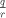 . Denote it by . Denote it by
 . Rewriting some . Rewriting some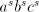 using such pairs we obtain using such pairs we obtain 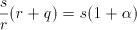
occurrences of  .
Continuing .
Continuing 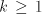 steps, we get steps, we get 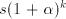 occurrences
of occurrences
of  , hence a geometrical progression, starting at , hence a geometrical progression, starting at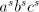 . . Symbols  can be also introduced in a derivation can be also introduced in a derivation 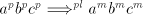 by using
pairs by using
pairs 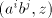 with containing occurrences of with containing occurrences of  . At most one such pair can
be used in a derivation step. Let . At most one such pair can
be used in a derivation step. Let 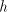 be the largest number of symbols be the largest number of symbols  in strings in strings
 as above (the number of such strings is finite). Thus, in a derivation as above (the number of such strings is finite). Thus, in a derivation
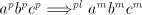 , the
number , the
number 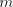 can be modified by such pairs in an interval can be modified by such pairs in an interval 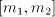 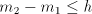 . . We start from at most 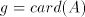 strings of the form strings of the form 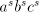 , hence we have at
most , hence we have at
most 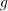 geometrical progressions geometrical progressions 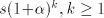 . The difference . The difference
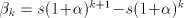 can be arbitrarily large. When can be arbitrarily large. When 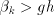 , the at most , the at most 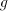 progressions can have an element
between progressions can have an element
between 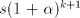 and and 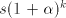 ; each such element can have
at most ; each such element can have
at most 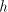 values. Consequently, at least
one natural number values. Consequently, at least
one natural number 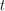 between between 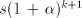 and and 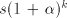 is not
reached, the corresponding string is not
reached, the corresponding string 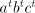 , although in , although in 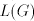 , is not in , is not in 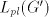 .
This contradiction concludes the proof of point (ii). .
This contradiction concludes the proof of point (ii). (iii) As only strings in the sets 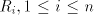 , of a grammar , of a grammar 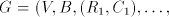 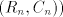 can be derived, we have can be derived, we have 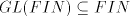 .
The inclusion .
The inclusion 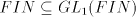 has been pointed out at the beginning of this section. has been pointed out at the beginning of this section. 
Corollary.
The families 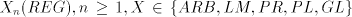 ,
contain non-context-free languages. ,
contain non-context-free languages. For 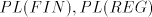 and and 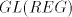 this assertion can be strenghtened. this assertion can be strenghtened. Theorem 2. Every propagating unary 0L language belongs to the family 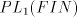 . . Proof. For a unary 0L system 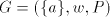 with with 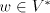 and and 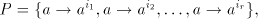
with
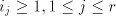 , we construct the shuffle grammar , we construct the shuffle grammar 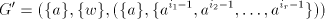
It is easy to see that 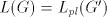 . . This implies that 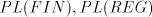 contain one-letter non-regular languages. This is not true
for the other modes of derivation. contain one-letter non-regular languages. This is not true
for the other modes of derivation. Theorem 3. A one-letter language is in 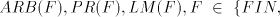 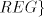 or in
or in 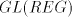 if and only if it is regular. if and only if it is regular. Proof. Take a shuffle
grammar 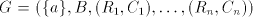 with
regular sets with
regular sets 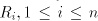 .
Clearly, .
Clearly, 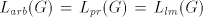 . Because we work with one-letter
strings, a string . Because we work with one-letter
strings, a string  can be derived using a component can be derived using a component 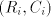 if (and only
if) the shortest string in if (and only
if) the shortest string in 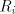 is contained in is contained in  , hence is of length at most , hence is of length at most 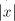 . Therefore we can replace each . Therefore we can replace each 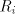 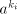 , where , where 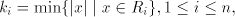
without modifying the generated language.
Denote Page 71
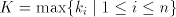
and construct the right-linear grammar 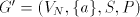 with with 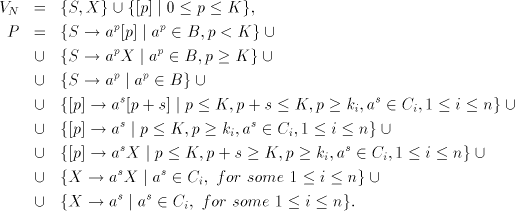
At the first steps of a derivation in 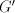 , the nonterminals , the nonterminals 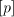 count the
number of symbols count the
number of symbols  introduced at that stage, in order to ensure the correct simulation of
components of introduced at that stage, in order to ensure the correct simulation of
components of 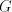 when this number exceeds when this number exceeds 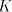 , then each component can be
used, and this is encoded by the nonterminal , then each component can be
used, and this is encoded by the nonterminal 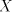 . Thus we have the equalities . Thus we have the equalities 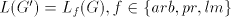 For the global derivation we start from an arbitrary shuffle grammar
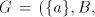 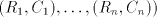 , with regular sets , with regular sets 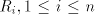 ,
take for each ,
take for each 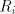 a deterministic finite automaton a deterministic finite automaton
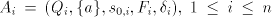 and construct the
right-linear grammar and construct the
right-linear grammar 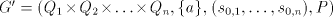 with 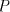 containing the following rules:
containing the following rules: 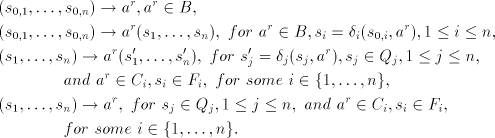
New occurrences of  , corresponding to sets , corresponding to sets 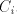 , are added (it does not
matter where) only when the current string belongs to , are added (it does not
matter where) only when the current string belongs to 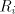 , and this is checked
by the simultaneous parsings of the current string in the deterministic automata
recognizing , and this is checked
by the simultaneous parsings of the current string in the deterministic automata
recognizing 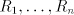 . Consequently, . Consequently, 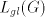 is a regular language. is a regular language. Conversely, each one-letter regular language 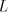 is known to be equal with the
disjoint union of a finite language is known to be equal with the
disjoint union of a finite language 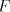 and a finite set of languages of the form and a finite set of languages of the form 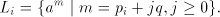 . .
(The constant 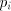 is associated to is associated to 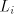 , but , but  is the same for all is the same for all 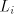 .)
Assume we have .)
Assume we have  languages languages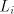 ; denote ; denote 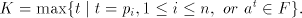
Then 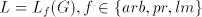 , for the grammar , for the grammar 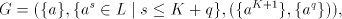
hence we have the theorem for 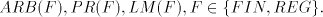 . . For the global case, starting from 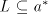 regular, written as above regular, written as above 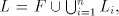 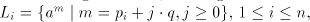 we consider the grammar 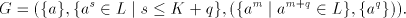
The equality 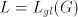 is obvious and this concludes the proof. is obvious and this concludes the proof. 
In view of the previous result, it is somewhat surprising to obtain Theorem 4. The family 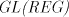 contains non-semilinear languages (even on
the alphabet with two symbols only). contains non-semilinear languages (even on
the alphabet with two symbols only). Proof. Consider the shuffle grammar 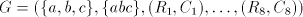 with the following eight components:
with the following eight components: Page 72
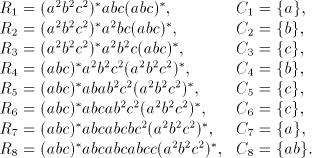
Examine the derivations in 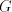 in the global mode. The whole current string
must be in some in the global mode. The whole current string
must be in some 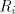 in order to continue the derivation. Assume we start from
a string in order to continue the derivation. Assume we start from
a string 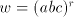 (initially we have (initially we have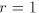 ). This string is in ). This string is in 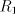 only,
hence we can add one more occurrence of only,
hence we can add one more occurrence of  . This can be done in all possible positions
of . This can be done in all possible positions
of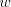 and we obtain a string in and we obtain a string in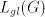 , but only when we obtain , but only when we obtain 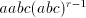 we can continue the derivation, namely by using the second component of
we can continue the derivation, namely by using the second component of 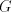 .
Now a symbol .
Now a symbol 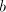 can be added, and again the only case which does not block the derivation
leads to can be added, and again the only case which does not block the derivation
leads to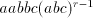 . We can continue with the third component and either
we block the derivation, or we get . We can continue with the third component and either
we block the derivation, or we get 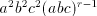 . From a string of the
form . From a string of the
form 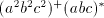 we can continue only with the first component, hence the
previous operations are iterated. When all symbols
we can continue only with the first component, hence the
previous operations are iterated. When all symbols 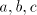 are doubled, we
obtain the string are doubled, we
obtain the string 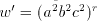 . . Note that 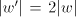 (more precisely, (more precisely, 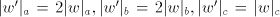 ), but for each intermediate string ), but for each intermediate string  in this derivation
at least one of the following inequalities holds: in this derivation
at least one of the following inequalities holds: 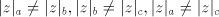 . .
To a string of the form of 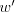 above only the fifth component of above only the fifth component of 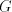 can
be applied and again either the derivation must be finished, or it continues
only in can
be applied and again either the derivation must be finished, or it continues
only in 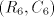 . The derivation proceeds deterministically through . The derivation proceeds deterministically through 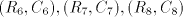 ,
inserting step by step new symbols ,
inserting step by step new symbols 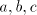 between pairs
of such symbols in order to obtain again triples between pairs
of such symbols in order to obtain again triples 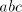 . In this way we obtain
either strings from which we cannot continue or we reach a string of the same form
with . In this way we obtain
either strings from which we cannot continue or we reach a string of the same form
with 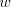 , namely , namely 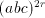 . The number of . The number of 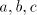 occurrences has been doubled
again, whereas in the intermediate steps we have strings with different numbers
of occurrences of at least two of . occurrences has been doubled
again, whereas in the intermediate steps we have strings with different numbers
of occurrences of at least two of . The process can be iterated. From the previous discussion one can see that for
all strings 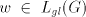 with with 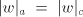 we also have we also have 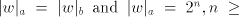 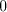 . . Consequently, denoting by 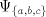 the Parikh mapping
with respect to the alphabet the Parikh mapping
with respect to the alphabet 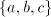 , we have , we have 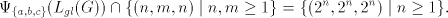 . .
This set is not semilinear; the set of semilinear vectors of given dimension is closed
under intersection, therefore 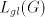 is not a semilinear language. is not a semilinear language. Consider now the morphism 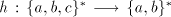 defined by defined by 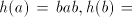 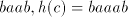 .
Define the grammar .
Define the grammar 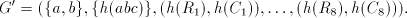
Shuffling a string 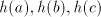 with a string with a string 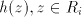 , in a way different
from inserting , in a way different
from inserting 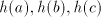 as a block leads to strings with substrings of the
forms as a block leads to strings with substrings of the
forms 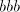 or or 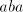 . Take, for example, . Take, for example, 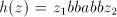 and examine the possibilities
to shuffle and examine the possibilities
to shuffle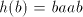 after after 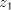 . In order to not get a substring . In order to not get a substring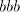 we must
insert the first symbol of we must
insert the first symbol of 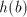 after the specified occurrence of after the specified occurrence of  in in 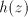 .
If we continue with the symbol .
If we continue with the symbol 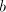 of of 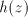 , this is as starting after this occurrence
of , this is as starting after this occurrence
of 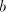 , if we continue with the symbol , if we continue with the symbol  of of 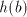 , then we obtain , then we obtain 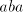 . Starting after . Starting after 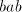 in in 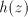 , after introducing one , after introducing one 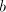 from from 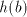 we either get we either get 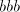 (if we continue in
(if we continue in 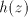 ), or ), or 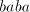 (if we alternate in (if we alternate in 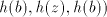 , or , or
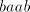 (hence (hence 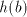 is inserted as a block). Similarly, take for example is inserted as a block). Similarly, take for example
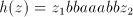 and shuffle the same and shuffle the same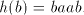 . Introducing . Introducing 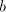 after after 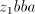 we have to continue either with
we have to continue either with  from from 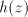 or with or with  from from 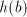 , in both
cases obtaining the subword , in both
cases obtaining the subword 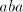 . The same result is obtained in all other cases.
After producing a substring . The same result is obtained in all other cases.
After producing a substring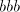 or or 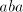 , the derivation is blocked. Inserting , the derivation is blocked. Inserting
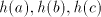 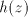 as a compact block corresponds to inserting as a compact block corresponds to inserting 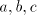 in
in . Consequently, the derivations in . Consequently, the derivations in 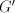 correspond to derivations in correspond to derivations in 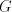 . When a derivation is blocked, it can terminate with a string . When a derivation is blocked, it can terminate with a string  with with 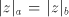 only when
only when  contains the same number of substrings contains the same number of substrings 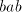 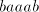 ,
with the possible exception of such substrings destroyed by the last shuffling, that
of ,
with the possible exception of such substrings destroyed by the last shuffling, that
of 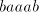 when using the pair when using the pair  or of or of 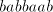 when using the pair when using the pair 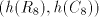 . . Moreover, 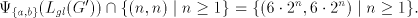 . .
Page 73
Indeed, from a string containing containing 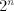 occurrences of every symbol occurrences of every symbol
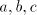 we get
a string we get
a string 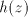 with with 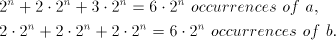
Conversely, if a string 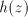 contains the same number of
contains the same number of  and and 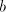 occurrences,
assume that it contains occurrences,
assume that it contains  substrings substrings 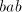 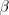 substrings substrings 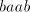 and
and 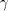 substrings substrings 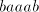 . Then it contains . Then it contains 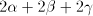 occurrences of
occurrences of 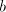 and and 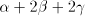 occurrences of occurrences of 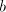 . Consequently, . Consequently, 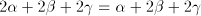
which implies 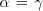 . As we have seen in the first part of the proof, when . As we have seen in the first part of the proof, when
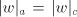 , then also , then also 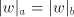 , hence , hence
 , too. Therefore
the obtained string , too. Therefore
the obtained string  corresponds to a string corresponds to a string  (in the sense (in the sense 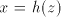 ) such
that ) such
that 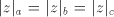 . This implies . This implies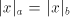 and and 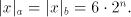 In conclusion, also 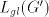 is not semi-linear. is not semi-linear. 
For the case of finite selection we have Theorem 5. 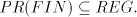 . . Proof. Let 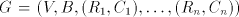 be a shuffle grammar with
all sets be a shuffle grammar with
all sets 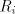 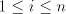 , finite. We construct a left-linear grammar , finite. We construct a left-linear grammar
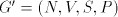 as follows. as follows. Let 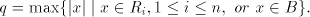 . .
Then 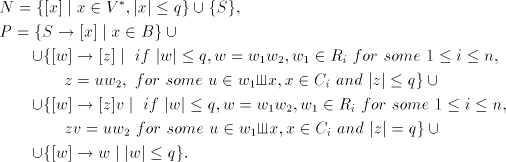
The derivation proceeds from right to left; the nonterminals 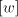 in the left-hand
side of sentential forms memorize the prefix in the left-hand
side of sentential forms memorize the prefix 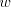 of large enough length to control
the derivation in of large enough length to control
the derivation in 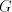 in the prefix mode. Therefore, in the prefix mode. Therefore,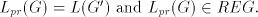 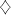
Theorem 6. 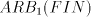 contains non-linear languages. contains non-linear languages. Proof. Take 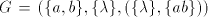 . We obviously
have . We obviously
have 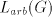 = the Dyck language over = the Dyck language over 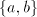 , known to be a (context-free)
non-linear language. , known to be a (context-free)
non-linear language. 
Open problems. Are there non-semilinear languages in families 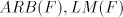 , , 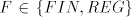 or in or in 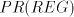 ? Are there non-context-free languages
in families ? Are there non-context-free languages
in families 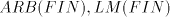 ? ? We proceed now to investigating the relations among families 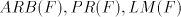
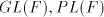 for for 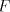 as above.
We present the results in the next theorem, whose proof will consist of the
series of lemmas following it. as above.
We present the results in the next theorem, whose proof will consist of the
series of lemmas following it. Theorem 7.
- (i)
- Each two of the families
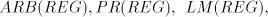
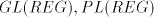 are incomparable, excepting the case of are incomparable, excepting the case of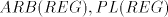 for which we have the proper inclusion
for which we have the proper inclusion 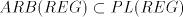 . . - (ii)
- Each
pair
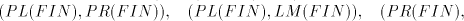 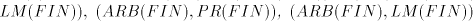 consists of incomparable families; the following
inclusions are proper: consists of incomparable families; the following
inclusions are proper: 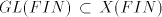 for all for all 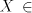 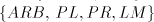 ,
and ,
and 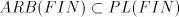 . .
Page 74
Lemma 1. For each 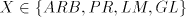 we have we have 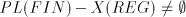 Proof. Follows from the fact that 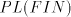 contains one-letter
non-regular
languages, but the one-letter languages in the other families contains one-letter
non-regular
languages, but the one-letter languages in the other families 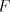 are regular
(Theorem 3). are regular
(Theorem 3). 
Lemma 2. 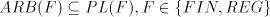 Proof. For a shuffle grammar 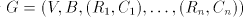 used in the arbitrary mode of derivation, construct
used in the arbitrary mode of derivation, construct 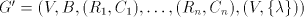 . . For 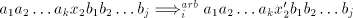 in in 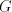 , with , with 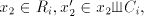 , for some , for some 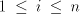 ,
we have ,
we have 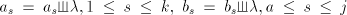 , hence , hence 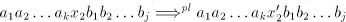 in in 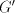 . . Conversely, a derivation in 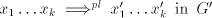 corresponds
to a derivation corresponds
to a derivation 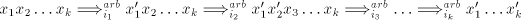 in in
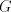 , with the steps , with the steps 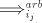 omitted when omitted when 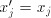 . . In conclusion, 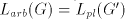 Lemma 3. The language 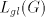 , for , for 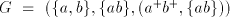 is not in
is not in 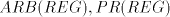 , or , or 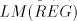 . . Proof. We have 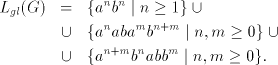
Assume that this language can be generated in one of the modes 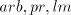 by a
grammar
by a
grammar 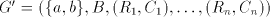 . Each string in . Each string in  contains the same number of occurrences of
contains the same number of occurrences of  and of and of  , hence for each string
in , hence for each string
in  which is used in a derivation we must have the same property. In the
mentioned modes which is used in a derivation we must have the same property. In the
mentioned modes 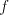 of derivation, if we have a derivation of derivation, if we have a derivation 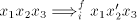 (for
(for 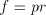 we have we have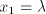 ) using a string ) using a string 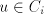 , then we can
obtain , then we can
obtain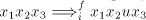 , too, hence the use of , too, hence the use of  can be iterated,
thus producing strings can be iterated,
thus producing strings 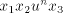 with arbitrary with arbitrary . For . For 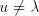 this is contradictory this is contradictory 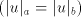 . . 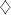
Lemma 4. The language 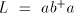 is in is in 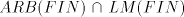 but not in but not in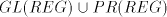 . . Proof. The language 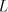 can be generated by the grammar can be generated by the grammar
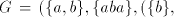 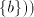 in both modes of derivation in both modes of derivation 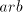 and and 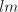 , but it cannot be generated
by any shuffle grammar in modes , but it cannot be generated
by any shuffle grammar in modes 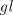 or or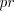 : in order to arbitrarily increase
the number of : in order to arbitrarily increase
the number of 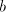 occurrences we have to use a string occurrences we have to use a string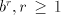 , which is
shuffled to a string containing the leftmost occurrence of the symbol , which is
shuffled to a string containing the leftmost occurrence of the symbol  in
the strings in in
the strings in 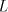 . In this way, strings beginning with . In this way, strings beginning with 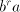 can be produced,
a contradiction. can be produced,
a contradiction. 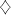
Lemma 5. The language 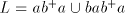 is in is in 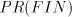 but not
in but not
in 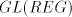 . . Proof. For 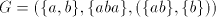 we have we have 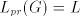 but
but 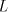 cannot be generated in the cannot be generated in the 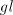 mode by any grammar: we need a string
u which introduces occurrences of mode by any grammar: we need a string
u which introduces occurrences of 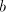 and in the global mode this and in the global mode this  can be adjoined
in the right hand of the rightmost occurrence of can be adjoined
in the right hand of the rightmost occurrence of  in the strings of in the strings of 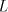 . .
Lemma 6. The language 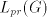 , for the grammar , for the grammar 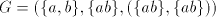 , is not in , is not in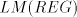 . . Proof. We have 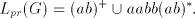
(When the leftmost two symbols are not 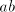 , the derivation is blocked.) , the derivation is blocked.) Assume that 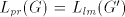 for some for some 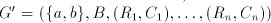 . For every . For every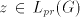 we have we have 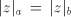 , hence the same
property holds for all strings in sets , hence the same
property holds for all strings in sets 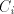 effectively used in derivations. Take
such a nonempty string effectively used in derivations. Take
such a nonempty string 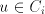 and examine the form of strings and examine the form of strings 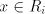 .
Such strings .
Such strings Page 75
cannot be prefixes of 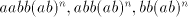 , because
otherwise we can
obtain parasitic strings by introducing , because
otherwise we can
obtain parasitic strings by introducing  in the left of the pair in the left of the pair 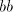 in
strings in
strings 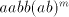 . Suppose that . Suppose that  is a prefix of is a prefix of 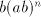 different
from different
from 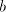 . Then we can shuffle the string . Then we can shuffle the string  in such a way to obtain a pair in such a way to obtain a pair
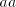 in the right of the pair in the right of the pair 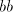 already existing in strings of the form already existing in strings of the form 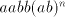 .
Again a contradiction, hence the strings of the form .
Again a contradiction, hence the strings of the form 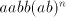 cannot be derived.
This implies that they are obtained by derivations of the form cannot be derived.
This implies that they are obtained by derivations of the form 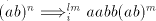 .
Consequently, also .
Consequently, also 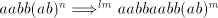 is possible
(we have found
that the prefix is possible
(we have found
that the prefix 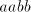 cannot be rewritten, hence the derivation is
leftmost). Such strings are not in cannot be rewritten, hence the derivation is
leftmost). Such strings are not in 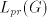 . . Lemma 7. The language 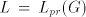 in the previous lemma is not
in the family in the previous lemma is not
in the family 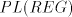 . . Proof. Assume that 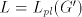 for some for some
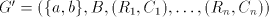 .
If a derivation .
If a derivation 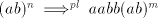 is possible in is possible in 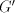 , then also , then also 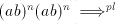 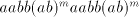 is possible, a contradiction.
Consequently, the strings is possible, a contradiction.
Consequently, the strings 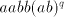 can be produced only by derivations of the
form can be produced only by derivations of the
form 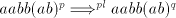 . . Assume that there is a derivation of the form 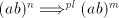 . . We cannot have pairs 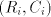 with with 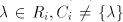 .
Indeed, if such a pair exists, then from a derivation .
Indeed, if such a pair exists, then from a derivation 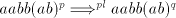 we can produce also
we can produce also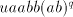 , for each , for each 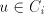 . . Examine the pairs 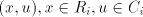 , used in the derivation , used in the derivation 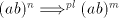 .
We know that .
We know that 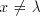 . If . If  contains a symbol contains a symbol  and also
and also  contains an occurrence of contains an occurrence of  , then we can produce strings having the
subword , then we can produce strings having the
subword 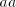 ; this is forbidden ( ; this is forbidden (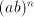 cannot generate strings of a form
different from cannot generate strings of a form
different from 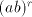 . Similarly, we cannot have occurrences of . Similarly, we cannot have occurrences of 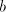 both in both in  and in and in  .
Therefore, .
Therefore, 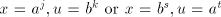 . Clearly, we must have . Clearly, we must have
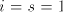 (no other subwords consisting of (no other subwords consisting of  or of or of 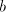 only appear in the derived
string) and only appear in the derived
string) and 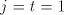 (no other subwords consisting of (no other subwords consisting of  or of or of 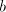 only appear in the produced
string). Such pairs only appear in the produced
string). Such pairs 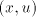 can be clearly used for producing a parasitic string, a
contradiction. can be clearly used for producing a parasitic string, a
contradiction. In conclusion, the strings 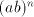 cannot be derived, hence such strings with
arbitrarily long cannot be derived, hence such strings with
arbitrarily long  must be obtained by derivations must be obtained by derivations 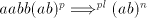 .
Then the symbols .
Then the symbols 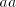 and and 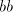 in the prefix of in the prefix of 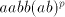 must be separated by
an occurrence of must be separated by
an occurrence of 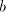 , respectively of , respectively of  . Irrespective whether this must be introduced
after the first . Irrespective whether this must be introduced
after the first 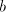 or before the second , we can introduce it
before the first , respectively after the second , thus preserving
the pair or before the second , we can introduce it
before the first , respectively after the second , thus preserving
the pair 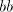 . If the pair . If the pair 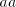 in its left-hand has been correctly shuffled with in its left-hand has been correctly shuffled with
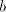 , then we obtain a string of the form , then we obtain a string of the form 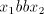 with with 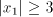 , which is
not in , which is
not in 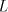 . The equality . The equality 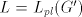 is impossible. is impossible. 
Lemma 8. There are languages in 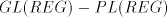 . . Proof. Consider the grammar 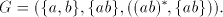 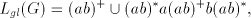 . .
We have , which is not a parallel shuffle language. The argument is similar to that in the previous proof, hence it is left to the reader. 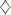
Lemma 9. There are languages in 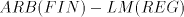 . . Proof. For the grammar 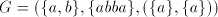 we have we have 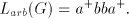
Assume that 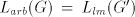 for some for some
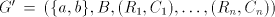 . For every . For every 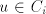 effectively used, we must have effectively used, we must have
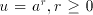 . No derivation can use a
pair . No derivation can use a
pair 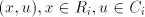 , with , with  containing a symbol containing a symbol 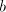 , otherwise we can produce strings
of the form , otherwise we can produce strings
of the form 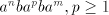 .
Consequently, all selectors .
Consequently, all selectors 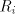 can be supposed to contain only strings in can be supposed to contain only strings in  . A pair . A pair  can be used in a derivation if (and only if) the
pair can be used in a derivation if (and only if) the
pair 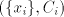 can be used, for can be used, for
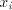 the shortest string in the shortest string in
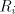 ; for two pairs ; for two pairs
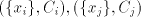 , only that with the shortest , only that with the shortest
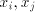 can be used. Denote can be used. Denote 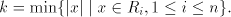
From a string 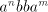 in in
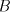 with with 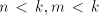 we can produce no other string; when we can produce no other string; when
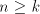 , we produce only strings of the
form , we produce only strings of the
form 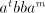 without modifying the
number without modifying the
number 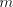 ; when ; when
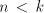 and and
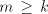 , then we , then we Page 76
can produce strings of the form
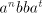 . However, . However,
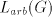 contains strings contains strings
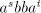 with simultaneously arbitrarily
large with simultaneously arbitrarily
large 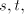 , a contradiction. , a contradiction. 
Lemma 10. The language generated by
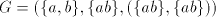 in the leftmost mode is not in in the leftmost mode is not in
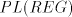 . . Proof. We have 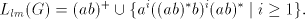 . .
Here is a derivation in in the leftmost mode: 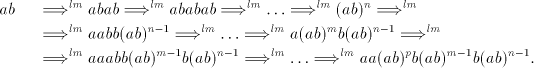
Assume that 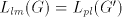 for some for some 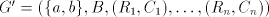 Examine the possibilities to obtain the strings 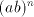 with
arbitrarily large with
arbitrarily large  . We cannot have a derivation . We cannot have a derivation 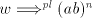 for for 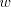 a string in
a string in 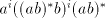 , , 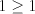 , because we must separate both the , because we must separate both the 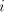 left occurrences of
left occurrences of  and the pairs and the pairs 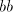 appearing in the string; irrespective
of the used strings to be shuffled we can do only part of these operations,
letting for instance a pair appearing in the string; irrespective
of the used strings to be shuffled we can do only part of these operations,
letting for instance a pair 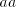 unchanged and separating all pairs unchanged and separating all pairs 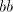 ; we
obtain a parasitic string. Therefore we must have derivations ; we
obtain a parasitic string. Therefore we must have derivations 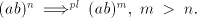 .
If in such a derivation we use a pair .
If in such a derivation we use a pair 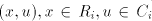 ,
such that ,
such that  occurs both in occurs both in  and in and in  , then we can produce strings with
substrings , then we can produce strings with
substrings 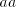 . Starting from a string . Starting from a string
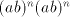 we can then produce strings
having we can then produce strings
having 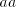 not in the left-hand end, a contradiction. It follows that symbols not in the left-hand end, a contradiction. It follows that symbols
 are introduced only by pairs are introduced only by pairs 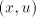 with with 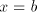 (no other subword of (no other subword of 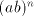 consists of only occurrences of
consists of only occurrences of 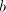 . In order to cover . In order to cover 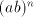 we must
use also pairs we must
use also pairs 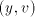 with with 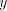 containing containing  and and  not containing .
This implies not containing .
This implies 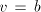 or or 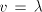 . The use of . The use of 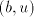 introduces at least one
new occurrence of introduces at least one
new occurrence of  for each for each 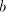 , hence, in order to keep the number of , hence, in order to keep the number of  and equal, we must have
and equal, we must have 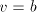 , which implies , which implies 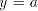 . Using such pairs
we can produce again strings containing pairs . Using such pairs
we can produce again strings containing pairs 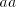 not in the left-hand end,
a contradiction which concludes the proof. not in the left-hand end,
a contradiction which concludes the proof. 
Let us note that in all previous lemmas the considered languages are generated by
grammars with only one component 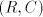 . Consequently, we have . Consequently, we have Corollary 1. For all families 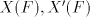 with with 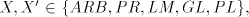 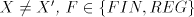 which are
incomparable, all which are
incomparable, all 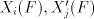 are incomparable, too, for every are incomparable, too, for every 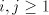 . . Corollary 2. Each family 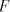 such that such that 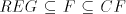 is incomparable
with each family is incomparable
with each family 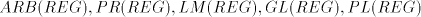 . . Proof. The fact that 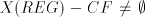 , for each , for each 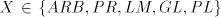 ,
has been already pointed out. On the other hand, the language ,
has been already pointed out. On the other hand, the language 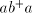 in
Lemma 4 is not in in
Lemma 4 is not in 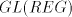 or in or in 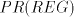 , and the language , and the language 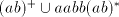 in Lemma 6
is not in in Lemma 6
is not in 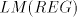 or on or on 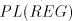 , hence it is not in , hence it is not in 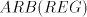 . These languages are regular,
which concludes the proof. . These languages are regular,
which concludes the proof. 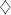
By a straightforward simulation in terms of context-sensitive grammars of checking the
conditions defining the correct derivation in a shuffle grammar and of performing
such a derivation, we get Theorem 8. All families 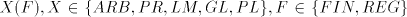 are strictly included in CS. are strictly included in CS. The properness of these inclusions follows from the previous Corollary 2. Page 77
4. The case of using maximal selectors
For a shuffle grammar 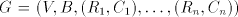 as in the previous
sections, we can also define the following mode of derivation: for as in the previous
sections, we can also define the following mode of derivation: for 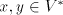 and and
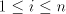 , write , write 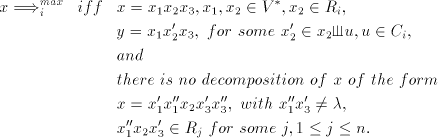
(We use 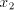 for shuffling only if no longer string can be used containing
that occurrence of for shuffling only if no longer string can be used containing
that occurrence of 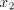 as a substring.) as a substring.) We denote by 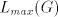 the language generated in this way and by the language generated in this way and by 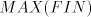 , , 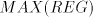 the corresponding families of languages. the corresponding families of languages. Lemma 11. 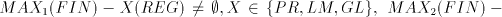 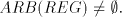 . . Proof. For 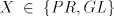 the assertion is proved by the language in
Lemma 4: in general, if the assertion is proved by the language in
Lemma 4: in general, if 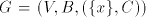 (one component, with a singleton
selector), then the maximality has no effect, the maximal derivations in (one component, with a singleton
selector), then the maximality has no effect, the maximal derivations in 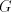 are arbitrary
derivations. This is the case with the grammar in Lemma 4. are arbitrary
derivations. This is the case with the grammar in Lemma 4. This is also true for the
grammar in the proof of Lemma 9; that language covers the case
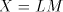 . . Consider now the grammar 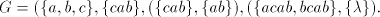 . .
Starting from a string 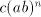 (initially we have (initially we have 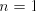 ), we can shuffle the string ), we can shuffle the string
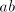 in the prefix in five essentially different ways: in the prefix in five essentially different ways: 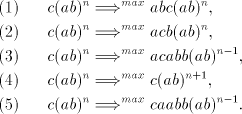
In cases (2) and (5) the derivation cannot continue (all selectors contain the subword
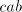 ; in cases (1) and (3) we cannot use the selector because ; in cases (1) and (3) we cannot use the selector because 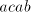 or or 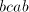 are present; the latter selectors entail the shuffle of are present; the latter selectors entail the shuffle of 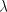 , which changes nothing,
hence the derivation is blocked. Only case (4) can be continued. Consequently, , which changes nothing,
hence the derivation is blocked. Only case (4) can be continued. Consequently, 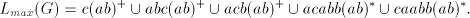 . .
This language cannot be generated by a shuffle grammar 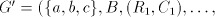 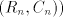 in the arbitrary mode.
Assume the contrary. Every string in in the arbitrary mode.
Assume the contrary. Every string in 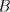 , in
a grammar , in
a grammar 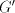 as above, must contain the symbol as above, must contain the symbol  and every string in and every string in 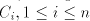 must contain the same number of occurrences of must contain the same number of occurrences of  and of and of 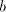 . If . If 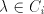 ,
then this string can be ignored without modifying the language of ,
then this string can be ignored without modifying the language of 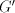 . In order to
generate strings . In order to
generate strings 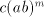 with arbitrarily large with arbitrarily large 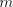 we must have derivation steps we must have derivation steps
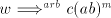 with with 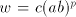 or or 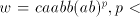 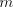 (the other strings
in (the other strings
in 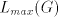 contain symbols contain symbols  or or 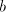 in front of in front of  ). Starting from ). Starting from 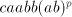 we have to introduce one occurrence of we have to introduce one occurrence of 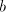 between symbols between symbols  in the substring in the substring 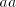 and one occurrence of and one occurrence of  between symbols between symbols 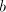 in in 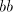 , that is we need a pair , that is we need a pair 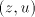 with with 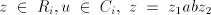 , and , and 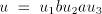 . Then from . Then from
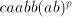 we can also produce we can also produce 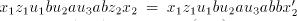 ,
a parasitic string. If ,
a parasitic string. If 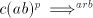 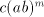 uses a pair uses a pair  with with 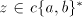 , then , then 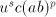 can be produced, for arbitrary can be produced, for arbitrary 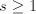 (we
introduce (we
introduce  in the left of in the left of  , thus leaving the occurrence of , thus leaving the occurrence of  in in 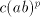 unchanged). Consequently, we have to use a pair unchanged). Consequently, we have to use a pair 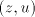 with with 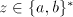 . More
exactly, . More
exactly,  is a substring is a substring Page 78
of 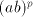 . As . As  contains occurrences of
both contains occurrences of
both  and and 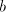 , we can derive , we can derive 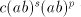 with arbitrary with arbitrary  (all such strings
are in (all such strings
are in 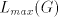 in such a way to
obtain in such a way to
obtain 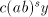 with with 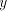 containing a substring containing a substring 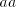 or a substring or a substring 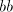 . Such a string
is not in . Such a string
is not in 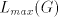 , hence the grammar , hence the grammar 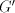 cannot generate strings cannot generate strings 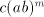 with arbitrarily large with arbitrarily large 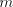 . The equality . The equality 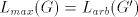 is impossible. is impossible. 
Lemma 12. 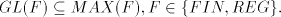 . . Proof. As 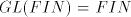 and, clearly, and, clearly, 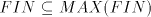 ,
the case ,
the case 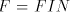 is obvious. is obvious. Take now a grammar
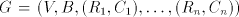 with regular with regular 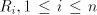 and construct and construct
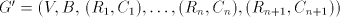 with with 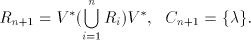 . .
We have 
- (
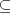 ) ) - If
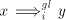 , that is , that is 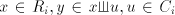 then the derivation is maximal, we also have then the derivation is maximal, we also have 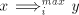 .
Consequently, if .
Consequently, if 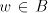 derives derives  in in 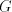 in the global mode, then in the global mode, then  derives derives  in in  in
the maximal mode. in
the maximal mode.
- (
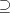 ) ) - Take a derivation
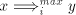 . If . If 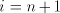 , then , then 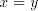 . If . If 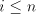 , then we have , then we have 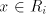 ,
otherwise the derivation is not allowed: for ,
otherwise the derivation is not allowed: for 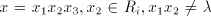 we have we have 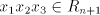 ,hence the derivation
in ,hence the derivation
in 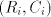 is not allowed. By induction on the length of derivations, we can now show
that for every maximal derivation in is not allowed. By induction on the length of derivations, we can now show
that for every maximal derivation in 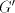 there is a global derivation in there is a global derivation in 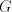 producing
the same string, hence producing
the same string, hence 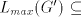 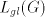 . .
Lemma 13 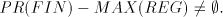 Proof. Consider the grammar 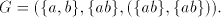
We obtain 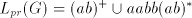 . .
This language is not in 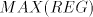 . Assume the contrary, that is . Assume the contrary, that is 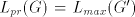 for some for some
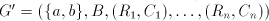 . . If we have a derivation of the form 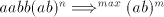 ,
then we have
to separate the symbols in the subwords ,
then we have
to separate the symbols in the subwords 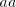 and and 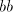 by by 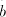 or some or some 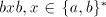 ,
and by ,
and by  or some or some 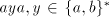 , respectively. To this aim, a string of
the form , respectively. To this aim, a string of
the form 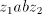 must be used as selector and a string must be used as selector and a string 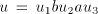 must be shuffled. But
then also must be shuffled. But
then also 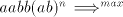 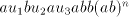 is possible, and this is not
in the language is possible, and this is not
in the language 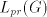 , a contradiction. , a contradiction. Assume that we have a derivation 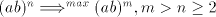 . Then
we must have . Then
we must have 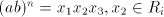 for some for some 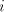 such that such that 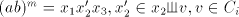 . Clearly, . Clearly, 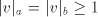 .
Then from .
Then from 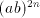 we can derive we can derive 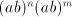 . If . If 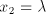 and and  starts by
an occurrence of starts by
an occurrence of 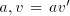 , then we can produce , then we can produce 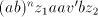 , for some , for some 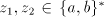 ; if ; if  starts
by starts
by 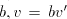 , then we can produce , then we can produce 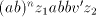 , for some , for some 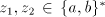 . No one of these
strings
is in . No one of these
strings
is in 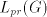 , a contradiction. Therefore we must have , a contradiction. Therefore we must have  . If . If
 contains the symbol contains the symbol  , then we can obtain , then we can obtain 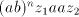 , for some , for some 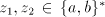 ,
by appropriate shuffling of ,
by appropriate shuffling of 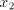 and and  . If . If 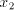 contains the letter contains the letter 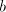 , then we can obtain , then we can obtain 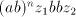 , for some , for some 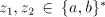 , by appropriate
shuffling. In both cases we have obtained parasitic strings. , by appropriate
shuffling. In both cases we have obtained parasitic strings. Consequently, the strings 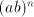 cannot be generated, they must be introduced as axioms;
this is impossible, because the set cannot be generated, they must be introduced as axioms;
this is impossible, because the set 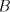 is finite, hence is finite, hence 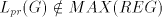 . . 
Lemma 14. A one-letter language is regular if and only if it is in 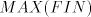 . . Proof. The proof of Theorem 3 shows the fact that every one-letter regular language
is in . Page 79
Conversely, take a grammar 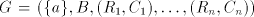 and write
each and write
each 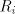 , , 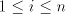 in the form in the form 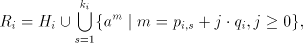
for 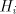 finite languages, and finite languages, and 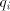 associated with associated with 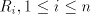 .
Denote .
Denote 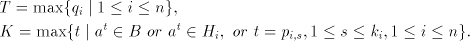
Take for each 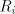 a deterministic finite automaton 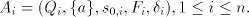 . .
We construct the right-linear grammar 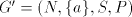 with with 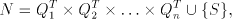
and 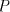 contains the following rules: contains the following rules: 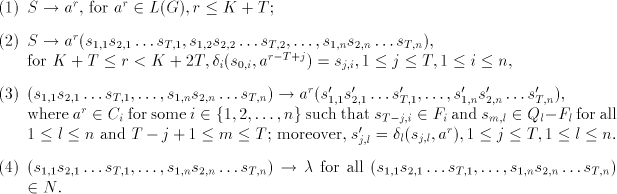 For every language For every language 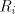 , the difference between the length of two consecutive strings
in is bounded by , the difference between the length of two consecutive strings
in is bounded by 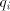 . Therefore the difference between two strings in any
of these languages is bounded by . Therefore the difference between two strings in any
of these languages is bounded by 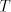 . In the nonterminals of . In the nonterminals of 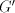 we memorize the last states used by the automata we memorize the last states used by the automata 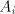 when recognizing the current string. A prolongation
to right is possible (by rules of type (3)) only according to that language when recognizing the current string. A prolongation
to right is possible (by rules of type (3)) only according to that language  which
contains the largest subword of the current string (thus we check the maximality). The
derivation can stop in any moment by rules of type (4). Consequently, which
contains the largest subword of the current string (thus we check the maximality). The
derivation can stop in any moment by rules of type (4). Consequently, 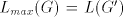 , hence , hence 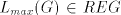 , which concludes the proof. , which concludes the proof. 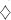
Summarizing these lemmas and the fact that 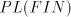 contains one-letter non-regular
languages, we obtain contains one-letter non-regular
languages, we obtain Theorem 9. 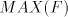 includes strictly includes strictly 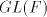 and is incomparable
with and is incomparable
with 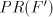 , , 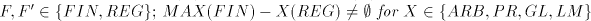 . . Open problems. Are the differences 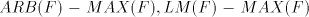 , , 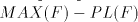 for for 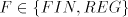 , non-empty ? , non-empty ? The diagram in figure 1 summarizes the results in the previous sections (an arrow
from 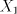 to to 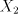 indicates the strict inclusion of the family . indicates the strict inclusion of the family . The maximal derivation discussed above can be considered as arbitrary-maximal, since
we are not concerned with the place of the selector in the rewritten string, but only
with its maximality. Similarly, we can consider prefix-maximal and leftmost
-maximal derivations,
when a maximal prefix or a substring which is both maximal and leftmost is used for
derivation, respectively. We hope to return to these cases. At least
the prefix-maximal case looks quite interesting. For instance, if the sets 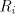 are
disjoint, then in every step of a derivation only one of them can be used, which decreases
the degree of nondeterminism of the derivations. are
disjoint, then in every step of a derivation only one of them can be used, which decreases
the degree of nondeterminism of the derivations. Page 80
5. Final remarks
We have not investigated here a series of issues which are natural for
every new considered generative mechanisms, such as closure and decidability
problems, syntactic complexity, or the relations with other grammars which do not use the rewriting
in generating languages. Another important question is whether or not the degree
of shuffle grammars induces an infinite hierarchy of languages. We
close this discussion by emphasizing the variety
of places where the shuffle operation proves to be useful and interesting, as
well as the richness of the area
of grammars based on adjoining strings. 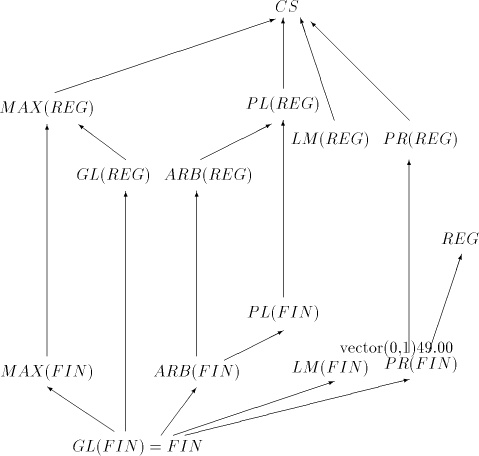
References
[1] B. Berard, Literal shuffle, Theoretical Computer Science, 51 (1987),
281 -- 299.
[2] J. Dassow, Gh. Paun, A. Salomaa, Grammars based on patterns,
Intern. J. Found. Computer Sci., 4, 1 (1993), 1 -- 14.
[3] B. C. Galiukschov, Polukontekstnie gramatiki, Mat. Logica i Mat. Ling.,
Kalinin Univ, 1981, 38 -- 50 (in Russ.).
[4] G. H. Higman, Ordering by divisibility in abstract algebra, Proc.
London Math. Soc., 3 (1952), 326 -- 336.
[5] M. Ito, G. Thierrin, S. S. Yu, Shuffle-closed languages, submitted, 1993.
[6] M. Jantzen, On shuffle and iterated shuffle, Actes de l'ecole de printemps
de theorie des langages (M. Blab, Ed.), Murol, 1981, 216 -- 235. Page 81
[7] A. K. Joshi, S. R. Kosaraju, H. M. Yamada, String adjunct grammars: I.
Local and distributed adjunction, Inform. Control, 21 (1972)
, 93 -- 116.
[8] S. Marcus, Contextual grammars, Rev. Roum. Math. Pures Appl., 14, 10
(1969), 1525 -- 1534.
[9] Al. Mateescu, Marcus contextual grammars with shuffled contexts,
in Mathematical Aspects of Natural and Formal Languages (Gh. Paun, ed.),
World Sci. Publ., Singapore, 1994, 275 -- 284.
[10] L. Nebesky, The $\xi$-grammar, Prague Studied in Math. Ling., 2 (1966),
147 -- 154.
[11] Gh. Paun, Grammars for Economic Processes, The Technical Publ.
House, Bucuresti, 1980 (in Romanian).
[12] Gh. Paun, Contextual Grammars, The Publ. House of the Romanian
Academy of Sciences, Bucuresti, 1982 (in Romanian).
[13] Gh. Paun, G. Rozenberg, A. Salomaa, Contextual grammars: Erasing, determinism,
one-sided contexts, in Developments in Language Theory (G. Rozenberg, A. Salomaa,
eds.), World Sci. Publ., Singapore, 1994, 370 -- 388.
[14] Gh. Paun, G. Rozenberg, A. Salomaa, Contextual grammars: Parallelism
and blocking of derivation, Fundamenta Informaticae, to appear.
[15] Gh. Paun, G. Rozenberg, A. Salomaa, Marcus contextual grammars: Modularity
and leftmost derivation, in Mathematical Aspects of Natural and Formal
Languages (Gh. Paun, ed.), World Sci. Publ., Singapore, 1994, 375 -- 392.
[16] G. Rozenberg, A. Salomaa, The Mathematical Theory of L Systems,
Academic Press, New York, London, 1980.
[17] A. Salomaa, Formal Languages, Academic Press, New York, London, 1973.
Page 82
|