| Submission Procedure |
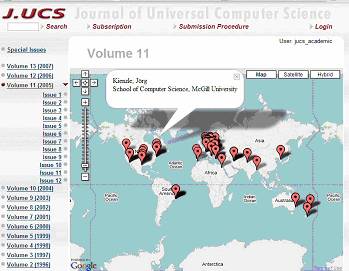
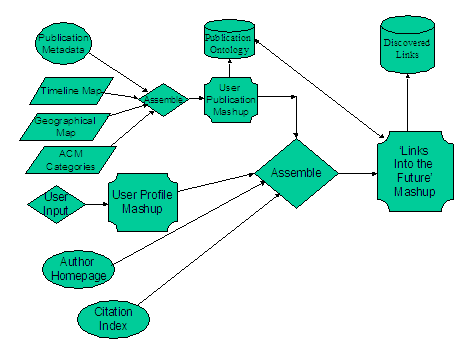
Mashups: Emerging Application Development Paradigm for a Digital JournalNarayanan Kulathuramaiyer Abstract: The WWW is currently experiencing a revolutionary growth due to its increasing participative community software applications. This paper highlights an emerging application development paradigm on the WWW, called mashup. As blogs have enabled anyone to become a publisher, mashups stimulate web development by allowing anyone to combine existing data to develop web applications. Current applications of mashups include tracking of events such as crime, hurricanes, earthquakes, meta-search integration of data and media feeds, interactive games, and as an organizer for web resources. The implications of this emerging web integration and structuring paradigm remains yet to be explored fully. This paper describes mashups from a number of angles, highlighting current developments while providing sufficient illustrations to indicate its potential implications. It also highlights the role of mashups in complementing and enhancing digital journals by providing insights into the quality academic content, extent of coverage, and the enabling of expanded services. We present pioneering initiatives for the Journal of Universal Computer Science in our efforts to harness the collective intelligence of a collaborative scholarly network. Keywords: Web 2.0, Mashups, visualisation Categories: H.3.4, H.3.5, H.3.7, H.4.3, H.5.1 1 IntroductionThe term Web 2.0, was coined by Tim O'Reilly [O'Reilly, 2005] to describe the revolutionary growth of the WWW which has now become a powerful platform for social networking. OhmyNews highlights the social engineering power of Web 2.0 with its notion of "news by the people for the people" by engaging over 41,000 "citizen journalists". [OhmyNews, 2006] The web thus incorporates a radical networked decentralisation to stimulate content creation and exchange by the masses. A new social computing platform has emerged supporting the extensive growth of e-communities built around social software applications such as Podcasting and Wikis. Podcasting facilitates the compilation, valuation and sharing of large amounts of media objects across the network by millions of users. The expanding role and influence of such services is thus effectively transforming e-communities. [Maurer and Schinagl, 2006]. Wikipedia, [Wikipedia, 2006] an encyclopedia that anyone can edit, has now more than 1.3 million collaboratively developed articles in English language. Blogs or Weblogs [see Blogger, 2006] have enabled almost anyone to become a publisher of contents, with the ability to remix content from a variety of sources. The "blogosphere" has enabled a massive global social network with communications mechanisms for instant responses and community feedback. Page 531 Collaborative applications such as MySpace [MySpace, 2006], Del.icio.us, [Del.icio.us, 2006] and Flickr [Flickr, 2006] have further enabled community sharing of thoughts, common interests and articles such as photographs, audio and video clips and bookmarks. The Business Week Online [Business Week, 2005] described the emergence of the 'millions of MySpace generation users' who spend up to several hours a day interacting with other users. The above-mentioned social computing environment has produced an explosive population of the web with socially generated content. There is an impending need to provide mechanisms to harness the collective intelligence of the masses, and to design well thought-off solutions to address particular concerns, including novel ideas in the area of digital libraries. This paper describes one such effort where we apply an emerging Web 2.0 applications development paradigm called mashups for a digital journal. Mashups have recently emerged as a powerful applications development platform that combines multiple sets of data streams into a unified user experience. This paper describes mashups and their role with regards to the evolution of the web, while highlighting their potentials and limitations as a mechanism for integrating and organising Web-resources to provide a richer Web experience. The emphasis on electronic journals can also be viewed as the heralding of a transformation for scholarly e-communities. 2 MashupsA mashup [Wikipedia, Mashup, 2006] is a website or web application that seamlessly combines content from one or more sources into an integrated experience. Content used in a mashup is typically provided by a public interface made available by a third party. Unlike Blogs and Wikis which are purely content population engines, mashups provide an added dimension by incorporating facilities for user-driven design and development of new applications. Mashups stimulate web development by allowing anyone to combine existing data from sources like eBay, Amazon, Google, Windows Live and Yahoo in innovative ways and therefore support a structuring capability for the integration of web content and applications. Asynchronous JAvascript over XML (AJAX) has made the Web interface appropriate for the development of applications such as mashups, as it allows requests to the server to be performed asynchronously. Really Simple Syndication, or RSS, provides a means of transferring micro-contents (snippets of content) between users, web sites and servers. These web feeds provide streams of inputs for mashups to be integrated into a unified environment. The Programmableweb [Programmableweb, 2007] has been an important resource in charting the development of mashups. According to the Programmableweb, the number of mashups exceeds 1800, and is growing steadily at the rate of approximately 3 mashups a day. Most of the current mashups are ad-hoc, non-commercial experiments, [Hinchclife 2006] built by hackers. Builders of mashups are considered hackers in the sense that they utilise code and data of others and link them together into independent applications. They are also referred to as mashup assemblers [as described by IBM, QEDWiki, 2007] as they integrate one or more application programmer interfaces (APIs). Page 532 There are many one-feature mashups, [Hinchclife, 2006] which are mainly built using a single API. Such mashups combine data and code together in the browser, using simple Javascript includes. They typically overlay application data such as real estate data, celebrity sightings, locations of restaurants, or the spread of diseases over a geographical map API to form useful and innovative applications. Multi-featured mapping mashups combine multiple resources, to further enrich the web experience. Although the mashup development rate has been increasing steadily, this growth rate is nowhere comparable to the growth rate of blogs. There are [as reported in Sirfi, 2006] over 75,000 blogs being tracked on Technorati [Technorati, 2006] daily. The non-availability of easy enough tools has affected the rapid development of mashups [Hinchclife, 2006]. Providers of APIs who make available components as building blocks for mashups are referred to as mashup enablers [as described by IBM, QEDWiki, 2007]. The availability of simple and lightweight APIs has opened up a great number of possibilities for mashup assemblers. The Programmableweb highlights that there are over four hundred APIs, which can serve as foundations for the development of an unlimited number of mashups. Google, Yahoo, Microsoft, Amazon and E-bay account for the most widely applied APIs [ProgrammableWeb]. We applied a task-oriented categorization of APIs to enable a better perspective of visualising the expanding list. The proposed categories include Mapping APIs, Search Services APIs, Social Networking and Community Management APIs, Commerce and Business Process APIs, Resources & Data Reference Services, Knowledge acquisition service, Communication services messaging and System Support services. 3 Data Integration Via MashupsA typical mashup locates and organizes data on a map or a customized user interface. Data from one or more sources is combined into an integrated experience. The availability of data is thus a crucial factor. A large number of mashups are being built in countries such as the US and Singapore, due to the greater availability of a wide range of public data. Numerous public databases are available, which include real estate, crime, weather and census data. Apart from this, a number of organizations also make their databases available as APIs for mashups assemblers to use. This includes multimedia databases, such as BBC's programmes, and access to research databases such as NCBI datasets and medical repositories [ProgrammableWeb, 2007]. Other types of Web data include search results, blog posts, results from question brokers and media objects such as photos, songs and video clips, etc. In situations where data is not available, mashups can also be applied to dynamically acquire data from user-input. Other forms of applications of mashups are the visualization of data sequences for navigation control, motion tracking, route tracing, flow control and temporal event tracking. Mashup Rendezvous [Mashup Rendezvous, 2006] demonstrates how Google Maps can be linked with Google Videos to provide movement tracking of persons and vehicles. Goggles Flight Simulator [Goggles 2007] is a game that simulates a fly-through on top of a Google Map's satellite images. Emailroutemap [Emailroutemap, 2006] allows the tracking of routes taken by an email over the internet. Page 533 4 Overview of Current MashupsCurrently available mashups can be broadly categorised as mapping mashups, timeline mashups, photo-organization mashups, meta-search mashups, custom-interface mashup, and content structuring mashups. These categories are not mutually exclusive and there can also be hybrid mashups combining two or more of these types. More than 40% of all current mashups are mapping mashups [ProgrammableWeb]. Mibazaar.com is an example of a Google maps based community website which consists of numerous geographical mashups. Mashups on this site provide matrimonial information, information on locations of place of worship, birthplaces of celebrities, top colleges, events, etc. Timeline mashups are often built upon calendar APIs [e.g. Google Calendar API, 2007]. An example of a timeline mashup is the Historical Marker Database [Historical Marker Database, 2007]. Photo organization mashups integrate Flickr photo images into a tag-based representation. The "Ten Best Flickr Mashups" [Calore, 2006] present creative mashups applications employing Flickr photo images. These mashups have shown how images can be mixed with other web resources to create innovative applications. These ideas will pave the way for future development of mashups application. Amazon Light [Amazon Light, 2006] is a custom interface mashup, which aggregates the back-end data and services of Amazon to create customized search that could be loaded faster. It combines results from Amazon, Google, and Yahoo into a single custom interface. Another example is QuickyWiki [QuickyWiki, 2006] which summarizes and simplifies lengthy Wikipedia articles. Meta-search interfaces such as A9 [Amazon, A9, 2006] supports the remixing of data in a form that suits a particular individual. It allows the combination of multiple existing search engines, data or environments to form a single new service. Meta-search mashups can be combined with custom interface mashups to enable the provision of personalized portals to suit individual needs. Content organization is important for organizing learning resources for knowledge management applications. Searchmapr [Searchmapr, 2006] is a content organisation mashup based on Treemaps [see Wikipedia, Treemaps, 2006]. Treemaps graphically visualize data to uncover inherent data patterns. Searchmapr combines Google search, Yahoo Images and Video search, del.icio.us bookmarks with the Trynt contextual term extraction [Trynt, 2007] and Yahoo's related suggestion service [Yahoo Developer Network, 2007]. This mashup highlights the information analysis capabilities that can be incorporated to build web content aggregation and information structuring applications. Topics of news stories are automatically generated by filtering and tagging news feeds. Such maps are also able to highlight temporal patterns in news focus. Another example of a content visualization mashup is LivePlasma [LivePlasma, 2006] which is a visually rich application that combines the Amazon API to show the relationship between movies, bands and actors. Page 534 Task specific context-based applications require the combining of geographical and timeline maps into a hybrid mashup. Attendr [Attendr, 2006] and Tabulator [Tim Berners Lee, 2006] are examples of hybrid mashups. Attendr is employed for managing events such as conferences, which keep track of localities of participants to build a social network for visualizing connections between them. This is a multi-feature mashup combining APIs from Google Maps, Yahoo Geocoding, Flickr and Technorati. Tabulator is an experimental mashup that explores the integration of maps, temporal information and content organization. We will now focus on what we consider a novel application of mashups for a digital journal, namely the Journal of Universal Computer Science (J.UCS) [J.UCS, 2007]. 5 Mashup Development for a Digital JournalJ.UCS is a unique electronic journal [as described in Liew, and Foo, 2001], having over 1500 publications over the past 12 years. It has incorporated a number of innovative features such as the enabling of semantic search and its annotative and collaborative features. It was one of the first electronic journals to have implemented features such as personal and public-annotations, multi-format publications, multi-categorization, etc. Many more novel ideas are being planned for J.UCS in the near future by a dedicated development team. This paper explores one of such ideas: a pioneering digital journal mashup. A mashup for a digital journal can serve both as a means of harnessing the social computing on the WWW and as an administrative support tool (to support rapid expansion). Mashups can be applied to provide rich collaborative media and content management facilities to support journal administration, structured academic publication, and to manage digital libraries of scholarly content. In our current experiments, we consider mapping mashups as a means of both supporting the development of multimedia content and of administering distributed users. 5.1 Preliminary ExperimentsOur initial experiments explored the visualization of the geographical distribution of authors and editors in an effort to determine distribution patterns and trends. J.UCS maintains the metadata for authors and editors, which includes their university, city and country information. A preliminary 2-feature mashup was developed to visualize this information of authors by integrating J.UCS metadata in conjunction with Google Map APIs [Google Map APIs]. Figure 1 illustrates the distribution of authors for a particular volume. As it can be seen in the Figure 1, the distribution of authors across the world can be visually mapped. The zooming feature may be employed to characterise both continent-level distribution as well as country specific distribution. Page 535 Figure 1: Distribution of authors for Volume 11 The development of the preliminary mashup revealed an interesting problem. The author metadata files contained the names of Universities (when the paper was submitted) and country information for all authors. However, 45% of the authors did not explicitly record their city location in the J.UCS' metadata files. As such, there was a need to first ensure that the metadata is up-to-date. Before the full visualisation of author distribution can thus be performed, either a manual effort of updating all empty fields, or an automated solution was required. Our initial pre-supposition was that it could be easily achieved via the access of Web search APIs and Web-enabled university directories. It was surprising for us to note that the university-locality search was not able to address the problem. The Geo-world database [Geo-world, 2007] provided us with the latitude and longitude information of all cities, but the mapping between universities and cities was not as easy to find. The university locality search via Google Map APIs was found to be inadequate for this purpose. The database integrated with the mapping APIs was found to be much smaller than that which can be accessed via Google Search. We then explored the possibility of discovering city names of universities by using Google search APIs with the information in the metadata (author name, university and country) to be used as search query. The identification of the respective city names for a university again turned out to be a challenge for a number of reasons. First of all, there is a difficulty in uniquely identifying a particular university. E.g. the search for National University California returned National University of San Diego, California National University (which offers online degrees) and the National University's Northern California Campuses (5 campuses were listed). Determining the correct location of a university therefore required human intervention. There were also many examples of retrieved university homepages which did not indicate a city name at all. Even when city names were mentioned, some universities had many campuses distributed over numerous localities, or only a postal address was mentioned. Page 536 A simpler solution was then employed where the parsing of university names was performed to identify the presence of a city name found in the world-cities database. The country name was used to disambiguate city names (i.e. Vienna, Virgina vs Vienna, Austria). For instance, this approach was able to infer that "Technological University Graz" was in Graz (by locating the string Graz). However, it was not possible to determine the location of Washington Business School of North Virginia, which is located in Vienna, Virginia. This simplistic approach increased the percentage of known (or inferred) author locations to 81%. The results were considered extremely useful as most of the inferred cities turned out to be correct. The validation of city names will still have to be performed manually. The team then resolved to employ a mashup to visualize and acquire feedback on the geo-locations of all authors. We will engage a smaller group of editorial assistants to validate the names of the cities as displayed on this mashup. Authors whose city information was not known, were visually positioned in the center of its respective country. The editorial assistants will then update the remaining locations of cities. The social power of the Web could also be engaged for such administrative tasks in the future. This mashup will also further enable the updating of other metadata on authors such as homepage and affiliation that may have changed. The information captured by the mashup does not in anyway change the original contact information of authors, but rather provides additional information about authors that will be stored in the comment field of publications. The updated information will also be maintained in the user profiles of authors. This will be an essential feature for J.UCS as the volume of papers is expected to expand and grow. As soon as this mashup has been made available to the public, it will also allow authors to check and verify information maintained in their own profiles. The additional meta-data will be useful for enabling further innovative features of the journal in future. 5.2 Further ExplorationsThe mashup described in section 5.1 will also produce a database of universities and their respective geo-codes. The data acquisition facility could be enhanced in the near future to capture the exact location of authors (precise building information). Although this information is not immediately required, it will be useful to highlight interesting patterns to answer questions such as: 'Who are all the experts in a particular field living nearby'. A company wishing to find experts in a particular field can then use this capability. Such human resource management capacity of mashups has not been explored largely. The J.UCS mashup initiative is thus considered pioneering for this reason. As highlighted by [Corsello, 2007] human resource driven enterprise mashup will be instrumental and is expected to become prevalent in the near future. Analytical tools and distribution patterns visualization capability will then add value to these potential applications. By further combining editor distribution with author distribution patterns, the mashup developed would serve as a useful tool for potential authors who are interested in the academic quality of the journal. The managing editor of the journal could immediately become aware of the extent of journal's geographical reach and universality. He would also be able to detect discrepancies or irregularities (i.e. cliques) [Khan et al, 2007]. Page 537 There is a need to ensure that the review process is diligently done. Visualization facilities of mashups can provide insights into the review process. By evaluating distribution patterns of individuals in conjunction with user profile information, (i.e. number of joint publications, membership in communities, etc.) it would be possible to validate (or invalidate) the partiality of reviews of editors. This may then serve as a tool for assigning impartial (neutral) reviewers to publications. For J.UCS, this ability will enhance our review process, especially in the acceptance of special issues of J.UCS. Numerous requests for the publication of special issues have been received based on collections of best papers from international conferences. A mashup will now be employed to enforce the review criterion that states that 'not more than 35% of papers should come from a single country' (to ensure that the conference was in fact international). Future enhancements planned will include mechanisms for visualization of social behavioral patterns of individuals. The implication of developing such a tool is invaluable as this capability can also be expanded to other academic appraisal tasks such as the promotion exercise. In the current state of the art, mashups do not support the incorporation of heuristic rules to provide data analysis. The incorporation of such functionality will allow mashups to become powerful knowledge management tools in the future. 6 Designing Future MashupsWe have demonstrated the use of mashups to support collaborative content development. It could however be further extended to offer customized and personalized services to the academic community. Mashups could also be employed to facilitate further value-adds to digital journals and their communities of practice. Future development of mashups can foster an interactive blended environment for organizations and institutions, providing multiple services for knowledge management. This includes the ability to visualize trails, data series, and events and the integration of multiple sources of contents in a variety of forms. Scholarly inputs can be incorporated to enable an identification of partners for collaboration, interesting papers in a specific area of research and to help gain in-depth insights on particular developments. In future, meta-mashups (mashups of mashups) are expected to emerge as social contexts for community applications. Meta-mashups will integrate multiple (component) mashups together with other application such as Wikis. Meta-mashups will consolidate the input, output and processing of multiple sources of data into multi-layered architectures in the realization of complex applications. These mashups could also dynamically incorporate semantic modeling to contextualise or personalize applications. One of the biggest challenges in the development of mashups has been the lack of design tools to facilitate development by a larger number of end-users. Such tools are beginning to emerge, [Yahoo Pipes, 2007] [Teqlo, 2007] but have not become widely adopted. These tools must become user friendly enough to allow non-computer experts to design useful applications. Page 538 In order to illustrate the use of such a design tool, we describe the development of an advanced meta-mashup for J.UCS to implement an innovative feature called 'links into the future' [as discussed by Afzal,et al, 2007]. The following diagram illustrates the data modeling for discovering links into the future. A data-acquisition (component) mashup has also to be employed to acquire information and update user profiles. Another (component) mashup is required to extract the context for links based on the known state of an author's publication. Figure 2 illustrates the design of this meta-mashup. The discovered links (relevant to an author's publication) will be dynamically appended to an author's publications as described by [Afzal, et al, 2007]. Human resource application of mashups as described in section 5.2 will also benefit from such a rigorous design process, as exemplified in Figure 2. We are thus exploring the usage of design tools for the development of re-usable components that can be applied in multiple Web applications. In this light, one can easily observe that the above design will also be instrumental in the establishment of a scholarly network of an academic community of practice. Further explorations with meta-mashups will be dealt with in future publications. Figure 2: Meta-Mashup Design for a Complex Application Page 539 7 ConclusionsThis paper has highlighted the development of mashups as an emerging paradigm for application development on the Web and has presented directions for building both simple as well as sophisticated mashup-based applications. A structured and systematic assembly of mashups is required for the development of multi-layer meta-mashups. We have demonstrated the benefits of employing a mashup for digital journals by the explorations carried out for J.UCS. Further developments by the J.UCS team will explore the realisation of a scholarly eco-system in providing personalized services and technology-supported administration within a collaborative social context. New features such as workflows and semantic maps will be incorporated to enable meaningful context-sensitive task-oriented applications. Acknowledgement The author would like to thank Professor Hermann Maurer for his invaluable insights on the various developments. References[Afzal et al, 2007] Afzal, M.T., Kulathuramaiyer, N., Maurer, H.,Creating Links to the Future, to appear in Journal of Universal Computer Science (http://www.jucs.org) [Amazon,A9, 2006] Amazon,A9, Homepage, http://www.a9.com, accessed 6 November 2006 [Amazon, 2006] Amazon, Homepage, http://www.amazon.com, accessed November 21, 2006 [Amazon Light, 2006] Amazon Light, Homepage, http://www.kokogiak.com/amazon, accessed 21 November 2006 [Attendr, 2006] Attendr, Homepage, http://attendr.com/ accessed 6 November 2006 [Blogger, 2006] Blogger, Homepage, http://www.blogger.com, accessed June 20, 2006 [BussinessWeek Online, 2005] BussinessWeek Online, MySpace Generation, http://www.businessweek.com/magazine/content/05_50/b3963001.htm, accessed November 7, 2006 [Calore, 2006] Calore, M, Ten Best Flickr Mashups, http://www.webmonkey.com/webmonkey/06/08/index4a_page2.html, accessed 21 Nov 2006 [Chicagocrime 2006] Chicagocrime, Homepage, http://www.chicagocrime.org, accessed 21 November 2006 [Corsello, 2007] Corsello, J, The Rise of Enterprise Mashups, The Human Capitalist, February 13, 2007, http://jasoncorsello.blogs.com/jason_corsellos_weblog/2007/02/the_rise_of_the.html [Del.icio.us 2006] Del.icio.us, Homepage, http://del.icio.us/, accessed November 21, 2006 [Ebay, 2006] Ebay, Homepage, http://www.ebay.com, accessed November 21, 2006 [Emailroutemap, 2006] Emailroutemap Homepage, http://map.butterfat.net/emailroutemap/, accessed 6 November 2006 Page 540 [Flickr, 2006] Flickr, Homepage, http://www.flickr.com/learn_more.gne, accessed November 21, 2006 [Geo-World, 2007], Geo-world Database [Goggles, 2007], Goggles, Homepage, http://www.isoma.net/games/goggles.html, accessed May 8, 2007 [Google Calendar API], Google Calendar API, Homepage, http://code.google.com/apis/calendar/overview.html, accessed May 8, 2007 [Google Map API, 2007], Google Map API, Homepage, http://www.google.com/apis/maps/, accessed May 8, 2007 [Hinchcliffe, 2006] Hinchcliffe, D, Making the Most of the Web: Creating Great Mashups, Web Mashup Styles Examined , accessed May 25, 2006 [Historical Marker Database, 2007] Historical Marker Database, Homepage, http://www.hmdb.org/, accessed 8 May 2007 [IBM, QEDWiki, 2007] IBM QED Wiki, Homepage, http://services.alphaworks.ibm.com/qedwiki/, accessed 8 May 2007 [J.UCS 2007] Journal of Universal Computer Science, http://www.jucs.org [Khan, et al, 2007] Khan, S.,Kulathuramaiyer, N.,Maurer, H.,Application of Mashups for a Digital Journal, to appear in J.UCS, Vol. 13, No. 4, 2007 [Kolbitsch, Maurer, 2006] Kolbitsch, J., Maurer, H. The Transformation of the Web: How Emerging Communities Shape the Information we Consume. Journal of Universal Computer Science, Vol. 12, No. 2, 187-213 [Liew and Foo, 2001] Liew, C.L., Foo, S. (2001): 'Electronic Documents: What Lies Ahead?', Proc 4th International Conference on Asian Digital Libraries (ICADL 2001), Bangalore, India, December 10-12, pp 88-105 [Liveplasma, 2006] Liveplasma, Homepage, http://www.liveplasma.com/, accessed 5 October 2006 [Mibazaar.com, 2006] Mibazaar.com, Homepage, http://www.mibazaar.com/, accessed 6 November 2006 [Mashup Rendezvous, 2006] Mashup Rendezvous, http://bhendrix.com/wall/Gmaps_GVideo_Mashup_Rendezvous.html accessed November 21, 2006 [Maurer and Schinagl, 2006] Maurer, H, Schinagl, W, (2006) "Wikis and Other E-communities are Changing the Web" Ed-Media, 2001 [MySpace, 2006], MySpace.com,Homepage, http://www.myspace.com/, accessed November 21, 2006 [OhmyNews, 2006] OhmyNews, Homepage, http://english.ohmynews.com, accessed November 6, 2006 [O'Reilly, 2006] O'Reilly, T., What Is Web 2.0 Design Patterns and Business Models for the Next Generation of Software http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html, accessed November 21, 2006. Page 541 [ProgrammableWeb 2007] ProgrammableWeb Homepage, http://www.programmableweb.com, accessed May 8, 2007 [QuickyWiki 2006] QuickyWiki, Homepage, http://www.quickywiki.com/, accessed 6 November 2006 [Roomformilk 2006] Roomformilk, Homepage, http://www.roomformilk.com/, accessed 6 November 2006 [Searchmapr, 2006] Searchmapr, Homepage, http://www.searchmapr.com/, accessed 6 November 2006 [Sifry, 2006] Sifry,D. State of the Blogosphere, April 2006 Part 1: On Blogosphere Growth, http://www.technorati.com/weblog/2006/04/96.html, accessed 7 November 2006 [Technorati, 2006], Technorati, Homepage, http://technorati.com/, accessed 7 November 2006 [Teqlo 2007], Teqlo, Homepage, http://www.teqlo.com/ accessed 6 May 2007 [Tim Berners-Lee, 2006] Tim Berners-Lee, Tabulator Project, Homepage, http://dig.csail.mit.edu/2005/ajar/ajaw/tab [Trynt, 2007], Trynt, Homepage, http://www.trynt.com/, accessed 8 May, 2007 [Wikipedia, 2006] Homepage, http://www.wikipedia.org, accessed April 17, 2006 [Wikipedia, Mashup 2006] Wikipedia, Mashup Homepage: http://en.wikipedia.org/wiki/Mashup_(web_application_hybrid), accessed November 22, 2006 [Wikipedia,Treemaps, 2006] Wikipedia, Treemaps, Homepage, http://en.wikipedia.org/wiki/Treemap, accessed 6 Novenber 2006 [Yahoo Developer Network, 2007] Yahoo Developer Network , Homepage http://developer.yahoo.com/, accessed 8 May 2007 [Yahoo Pipes, 2007] Yahoo Pipes, Homepage, http://pipes.yahoo.com/pipes/, accessed 6 May, 2007 Page 542 |
|||||||||||||||||